import asyncio
import os
import random
import logging
import hashlib
from typing import List, Dict
import aiosqlite
from telethon import TelegramClient
from telethon.tl.types import MessageMediaDocument, DocumentAttributeVideo, Message
from telethon.errors import (
FloodWaitError,
SecurityError,
FileReferenceExpiredError,
rpcerrorlist
)
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# ==================== 📁 文件夹初始化 ====================
DB_FOLDER = "database"
SESSION_FOLDER = "session"
for folder in [DB_FOLDER, SESSION_FOLDER]:
if not os.path.exists(folder):
os.makedirs(folder)
# ==================== 🛠️ 配置读取帮助函数 ====================
def get_env_float(key, default=0.0):
val = os.getenv(key, "")
if not val: return default
try:
return float(val)
except ValueError:
print(f"⚠️ 配置错误: {key} 必须是数字,当前为 '{val}',已重置为 {default}")
return default
def get_env_int(key, default=0):
val = os.getenv(key, "")
if not val: return default
try:
return int(val)
except ValueError:
return default
# ==================== ⚙️ 基础配置 ====================
API_ID = get_env_int("API_ID")
API_HASH = os.getenv("API_HASH")
PHONE_NUMBER = os.getenv("PHONE_NUMBER")
MIN_SIZE_MB = get_env_float("MIN_SIZE_MB", 0)
MAX_SIZE_MB = get_env_float("MAX_SIZE_MB", 0)
MIN_DURATION = get_env_int("MIN_DURATION", 0)
MAX_DURATION = get_env_int("MAX_DURATION", 0)
STOP_AFTER_DUPLICATES = 100
MAX_SCAN_COUNT = 22000
MIN_INTERVAL = 2
MAX_INTERVAL = 5
ALBUM_WAIT_TIME = 3.0
# ==================== 📋 任务清单 ====================
TASK_CONFIG = [
# ADULT INDUSTRY 到 town1
{
"sources": [-1001245945922],
"target": -xxx,
"limit": 300
},
]
# ==================== 日志初始化 ====================
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(message)s",
datefmt="%H:%M:%S"
)
logger = logging.getLogger("AutoBot")
# --- 修改:Session 路径移动到 session 文件夹 ---
session_path = os.path.join(SESSION_FOLDER, "user_session")
client = TelegramClient(session_path, API_ID, API_HASH)
# 全局状态变量
forward_queue = None
pending_albums = {}
album_timers = {}
db = None
# ==================== 🗄️ 数据库类 ====================
class AsyncDB:
def __init__(self, path):
self.path = path
self.conn = None
self.lock = asyncio.Lock()
async def connect(self):
self.conn = await aiosqlite.connect(self.path)
await self.conn.execute("CREATE TABLE IF NOT EXISTS videos (video_key TEXT PRIMARY KEY)")
await self.conn.commit()
async def close(self):
if self.conn: await self.conn.close()
async def seen(self, key):
async with self.lock:
async with self.conn.execute("SELECT 1 FROM videos WHERE video_key=?", (key,)) as cursor:
return await cursor.fetchone() is not None
async def mark(self, key):
async with self.lock:
await self.conn.execute("INSERT OR IGNORE INTO videos (video_key) VALUES (?)", (key,))
await self.conn.commit()
# ==================== 🛠️ 核心工具函数 ====================
def get_unique_key(msg: Message) -> str:
return f"{msg.chat_id}_{msg.media.document.id}"
def generate_safe_filename(sources: List[int], target: int) -> str:
"""修改:确保文件名包含文件夹路径"""
sources_str = "_".join([str(abs(s)) for s in sources])
target_str = str(abs(target))
if len(sources_str) > 50:
hash_object = hashlib.md5(sources_str.encode())
short_hash = hash_object.hexdigest()[:8]
preview = "_".join([str(abs(s)) for s in sources[:2]])
fname = f"{preview}_etc_{short_hash}_to_{target_str}.db"
else:
fname = f"{sources_str}to{target_str}.db"
# 拼接数据库文件夹路径
return os.path.join(DB_FOLDER, fname)
def is_video(msg: Message) -> bool:
if not msg.media or not isinstance(msg.media, MessageMediaDocument):
return False
doc = msg.media.document
if not doc.mime_type.startswith("video"):
return False
video_attr = next((a for a in doc.attributes if isinstance(a, DocumentAttributeVideo)), None)
if getattr(video_attr, "round_message", False):
return False
size_mb = doc.size / (1024.0 * 1024.0)
if MIN_SIZE_MB > 0 and size_mb < MIN_SIZE_MB: return False
if MAX_SIZE_MB > 0 and size_mb > MAX_SIZE_MB: return False
if video_attr:
duration = video_attr.duration
if MIN_DURATION > 0 and duration < MIN_DURATION: return False
if MAX_DURATION > 0 and duration > MAX_DURATION: return False
return True
# ==================== 🔄 异步逻辑 ====================
async def process_album_later(grouped_id):
try:
await asyncio.sleep(ALBUM_WAIT_TIME)
if grouped_id in pending_albums:
messages = pending_albums.pop(grouped_id)
album_timers.pop(grouped_id, None)
if messages:
messages.sort(key=lambda x: x.id)
await forward_queue.put(messages)
except asyncio.CancelledError:
pass
async def queue_message(message: Message):
if message.grouped_id:
gid = message.grouped_id
if gid not in pending_albums: pending_albums[gid] = []
pending_albums[gid].append(message)
if gid in album_timers: album_timers[gid].cancel()
album_timers[gid] = asyncio.create_task(process_album_later(gid))
else:
await forward_queue.put([message])
async def worker(target_channel_id):
processed_count = 0
while True:
try:
batch = await forward_queue.get()
if batch is None:
forward_queue.task_done()
break
files = [m.media for m in batch]
caption = batch[0].text or ""
try:
await client.send_file(target_channel_id, files, caption=caption)
processed_count += len(batch)
logger.info(f"✅ 发送成功 | 本次: {len(batch)} | 总计: {processed_count}")
for m in batch:
await db.mark(get_unique_key(m))
await asyncio.sleep(random.uniform(MIN_INTERVAL, MAX_INTERVAL))
except FloodWaitError as e:
logger.warning(f"⏳ 触发流控: 暂停 {e.seconds} 秒")
await asyncio.sleep(e.seconds + 2)
except FileReferenceExpiredError:
logger.error("❌ 文件引用过期,跳过")
except Exception as e:
logger.error(f"❌ 发送异常: {e}")
forward_queue.task_done()
except Exception as e:
logger.error(f"Worker Error: {e}")
async def scanner(source_channels, forward_limit):
all_collected_videos = []
for ch in source_channels:
channel_collected = 0
logger.info(f"🔍 正在扫描: {ch} (目标: {forward_limit})")
consecutive_duplicates = 0
scanned_count = 0
async for msg in client.iter_messages(ch, limit=MAX_SCAN_COUNT):
scanned_count += 1
if scanned_count % 200 == 0:
print(f"\r ...扫描深度: {scanned_count} 条", end="")
if not is_video(msg): continue
if await db.seen(get_unique_key(msg)):
consecutive_duplicates += 1
if consecutive_duplicates >= STOP_AFTER_DUPLICATES:
print(f"\n🛑 [频道 {ch}] 连续 {STOP_AFTER_DUPLICATES} 条重复,停止扫描。")
break
else:
consecutive_duplicates = 0
all_collected_videos.append(msg)
channel_collected += 1
print(f"\r📦 [频道 {ch}] 命中: {channel_collected}/{forward_limit}", end="")
if channel_collected >= forward_limit:
print(f"\n✅ [频道 {ch}] 额度已满")
break
print("")
if all_collected_videos:
logger.info(f"📊 找到 {len(all_collected_videos)} 个新视频。排序入队...")
all_collected_videos.sort(key=lambda x: x.date)
for msg in all_collected_videos:
await queue_message(msg)
if pending_albums:
logger.info("⏳ 等待相册分组...")
while pending_albums or album_timers:
finished = [k for k, t in album_timers.items() if t.done()]
for k in finished: del album_timers[k]
if not album_timers and not pending_albums: break
await asyncio.sleep(0.5)
else:
logger.info("⚠️ 没有发现任何新视频。")
await forward_queue.put(None)
async def run_single_task(task):
global db, forward_queue, pending_albums, album_timers
sources = task['sources']
target = task['target']
limit = task.get('limit', 200)
# 这里 generate_safe_filename 已经包含 database 路径
full_db_path = generate_safe_filename(sources, target)
logger.info(f"\n🚀 >>> 启动任务: {os.path.basename(full_db_path)} <<<")
# 彻底重置状态
forward_queue = asyncio.Queue()
pending_albums = {}
album_timers = {}
db = AsyncDB(full_db_path)
await db.connect()
worker_task = asyncio.create_task(worker(target))
try:
await scanner(sources, limit)
await forward_queue.join()
except Exception as e:
logger.error(f"❌ 任务运行异常: {e}")
finally:
if not worker_task.done():
worker_task.cancel()
await db.close()
logger.info(f"🏁 >>> 任务结束: {os.path.basename(full_db_path)} <<<\n")
# ==================== 🚀 主程序入口 ====================
async def main():
print("="*50)
print("🎥 Auto-Forwarder Pro (Task Sequencer)")
print(f"📉 最小视频限制: {MIN_SIZE_MB} MB")
print(f"📈 最大视频限制: {MAX_SIZE_MB if MAX_SIZE_MB > 0 else '不限'} MB")
print("="*50)
if not TASK_CONFIG:
logger.error("❌ TASK_CONFIG 为空,请在代码中配置任务列表!")
return
await client.start(PHONE_NUMBER)
try:
total_tasks = len(TASK_CONFIG)
for index, task in enumerate(TASK_CONFIG):
await run_single_task(task)
if index < total_tasks - 1:
wait_sec = 10
logger.info(f"⏳ 任务 [{index + 1}/{total_tasks}] 已完成。")
logger.info(f"⏳ 冷却中... {wait_sec} 秒后执行下一个任务...")
await asyncio.sleep(wait_sec)
else:
logger.info("🎉 所有任务已按顺序执行完毕!")
except KeyboardInterrupt:
print("\n👋 用户手动停止程序")
except Exception as e:
logger.error(f"🔥 系统致命错误: {e}")
finally:
await client.disconnect()
logger.info("🔌 已安全退出并断开连接")
if __name__ == "__main__":
asyncio.run(main())分类: Uncategorized
ClawCloudRunSSL
vless://82351ae8-64d4-4b87-8adb-06775f040873@wk.bablo.eu.cc:443?encryption=none&security=tls&sni=wk.bablo.eu.cc&fp=chrome&insecure=0&allowInsecure=0&type=ws&host=wk.bablo.eu.cc&path=%2F#edgetq103
vless://f19aa64c-0de7-4475-9776-ba2f306b4b46@wk.titt.eu.cc:443?encryption=none&security=tls&sni=wk.titt.eu.cc&fp=chrome&insecure=0&allowInsecure=0&type=ws&host=wk.titt.eu.cc&path=%2F#edgetownzzr
vless://bddc0e40-b38e-4cf7-b59b-e7bfd1a53b3d@wk.an.ccwu.cc:443?encryption=none&security=tls&sni=wk.an.ccwu.cc&fp=chrome&insecure=0&allowInsecure=0&type=ws&host=wk.an.ccwu.cc&path=%2F#edgetown7850
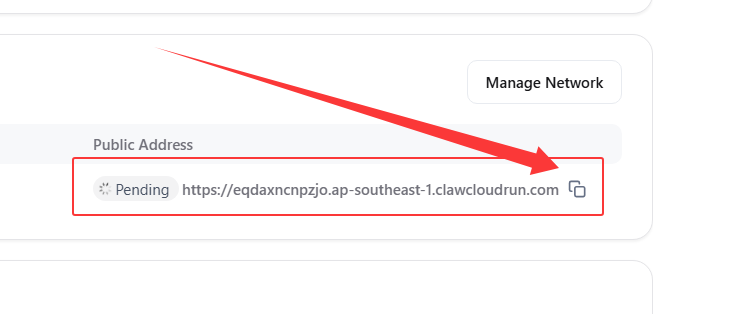
近期小伙伴部署爪云容器出现SSL证书一直提示
Pending的问题,长时间等待或更换工作区也无法解决。
所以这篇教程就来了,我们可以通过使用 Cloudflare 或 EdgeOne 来解决SSL证书问题,顺便给你的爪云容器套上CDN进行加速。🔧 配置 CDN
⚡ EdgeOne CDN
- 优点:低延迟,回源规则不设限制,支持多级域名。
- 缺点:
- 不支持免费域名,需要付费域名。
- 超长时间连接限速500Kbps,只适用于小流量项目。
🚀 点击展开 部署图文教程
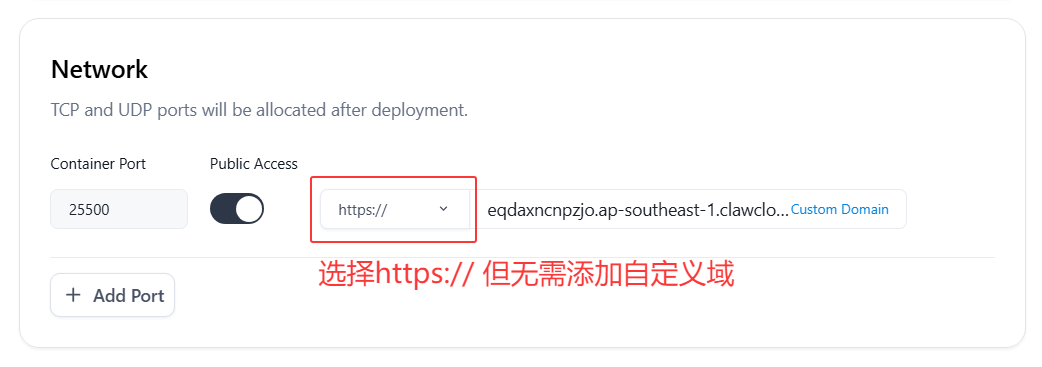
1️⃣ 记录爪云容器的域名
- 确认协议选择
https://,返回右上角点击Update更新部署。- 记录容器域名的部分,不包含
https://,例如eqdaxncnpzjo.ap-southeast-1.clawcloudrun.com2️⃣ 前往 EdgeOne 添加一个
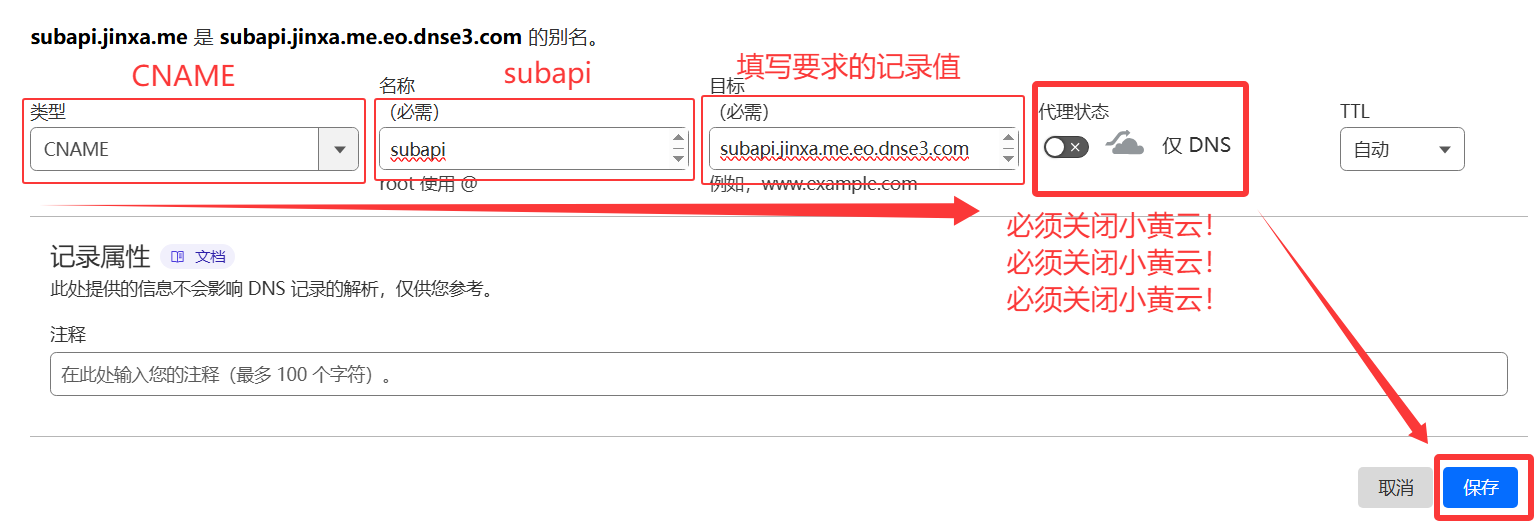
CNAME 接入域名
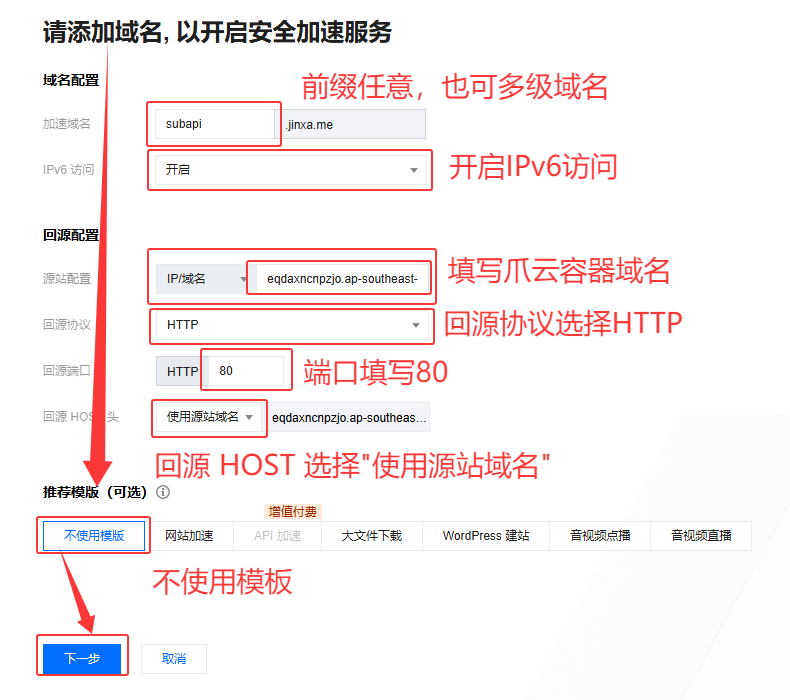
- 域名配置
- 加速域名:
subapi(前缀随意填写,也可填写多级域名)- IPv6 访问:
开启- 回源配置
- 源站配置:
IP/域名>eqdaxncnpzjo.ap-southeast-1.clawcloudrun.com(填写爪云容器的域名)- 回源协议:
HTTP- 回源端口:
80- 回源 HOST 头 :
使用源站域名- 推荐模板
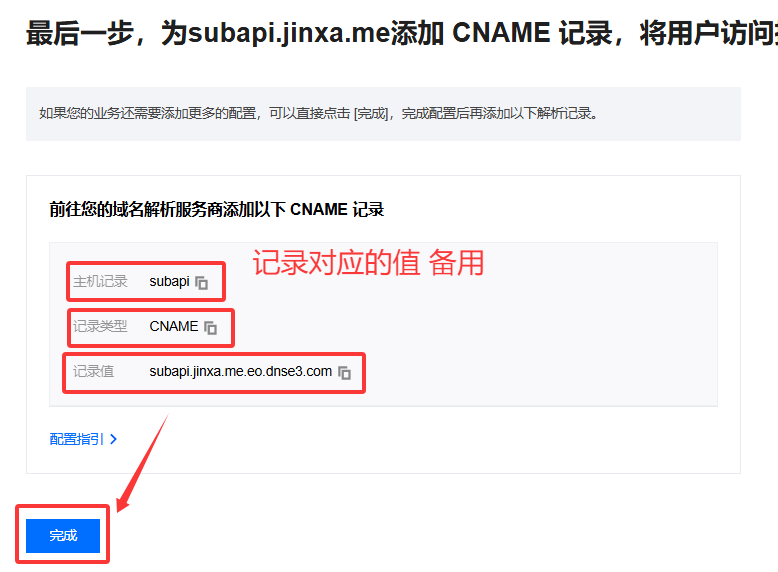
3️⃣ 记录对应的值
4️⃣ 前往域名服务商添加 CNAME 记录。
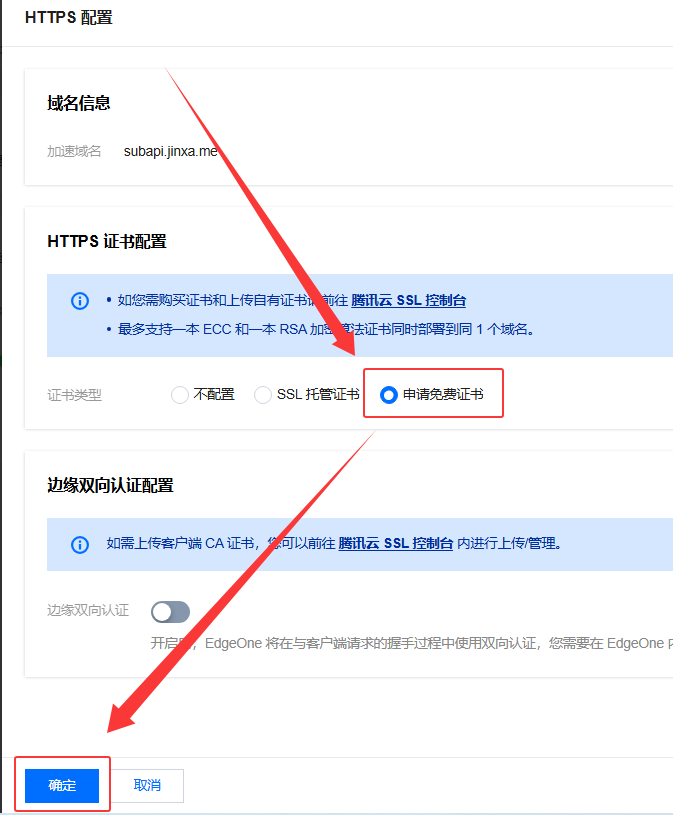
5️⃣ 等待生效后配置SSL证书
6️⃣ 完成!访问自定义域
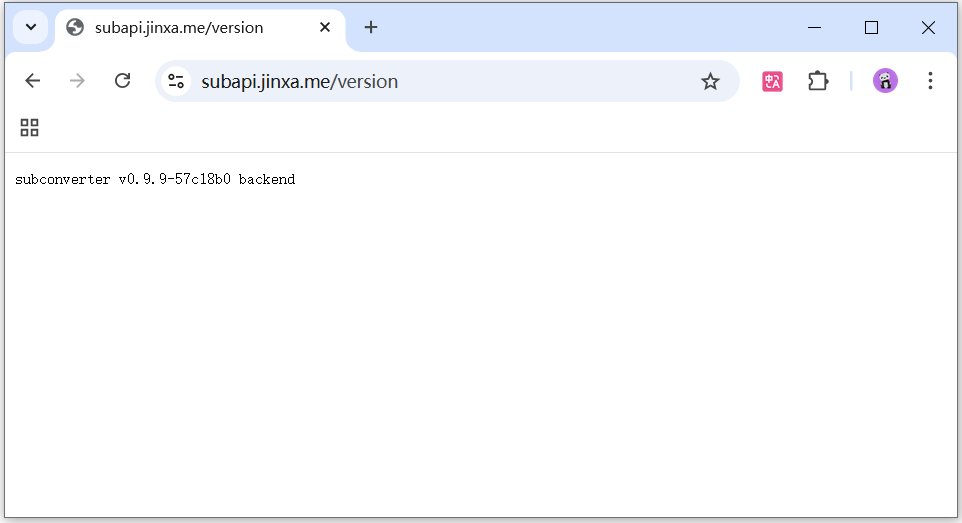
等待几分钟,成功申请免费证书后,访问 例如
https://subapi.jinxa.me/version即可访问到爪云容器。
☁️ Cloudflare CDN
- 优点:支持免费域名(除了双向解析的域名),例如
dpdns.org、us.kg等等。- 缺点:
- 占用TCP端口额度
- 配置过于复杂,需要添加
更改端口(Origin Rules)和配置规则(Configuration Rules),免费用户只能添加10条规则。- 只能使用次级域名,例如
example.dpdns.org,更多的次级层域名不会自动添加SSL证书。🚀 点击展开 部署图文教程
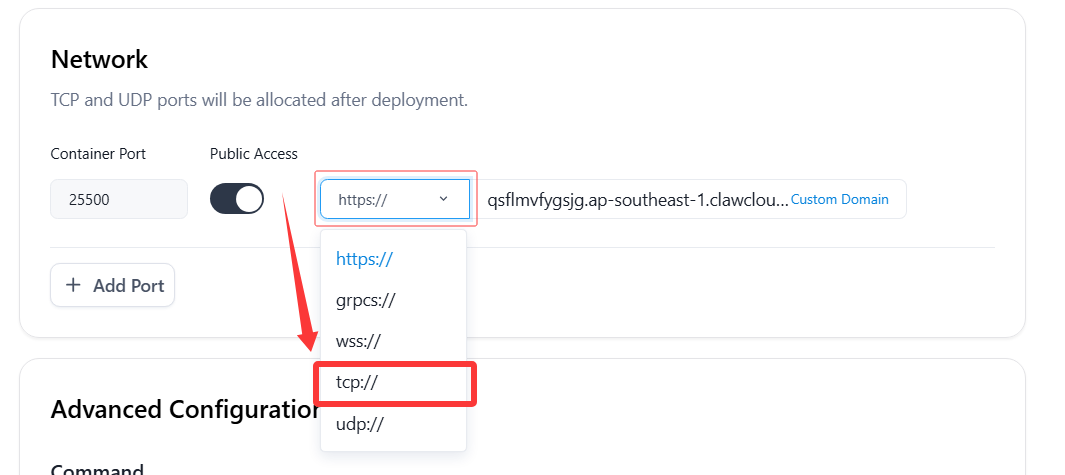
1️⃣ 切换服务为TCP模式
- 将需要套CDN的端口服务从
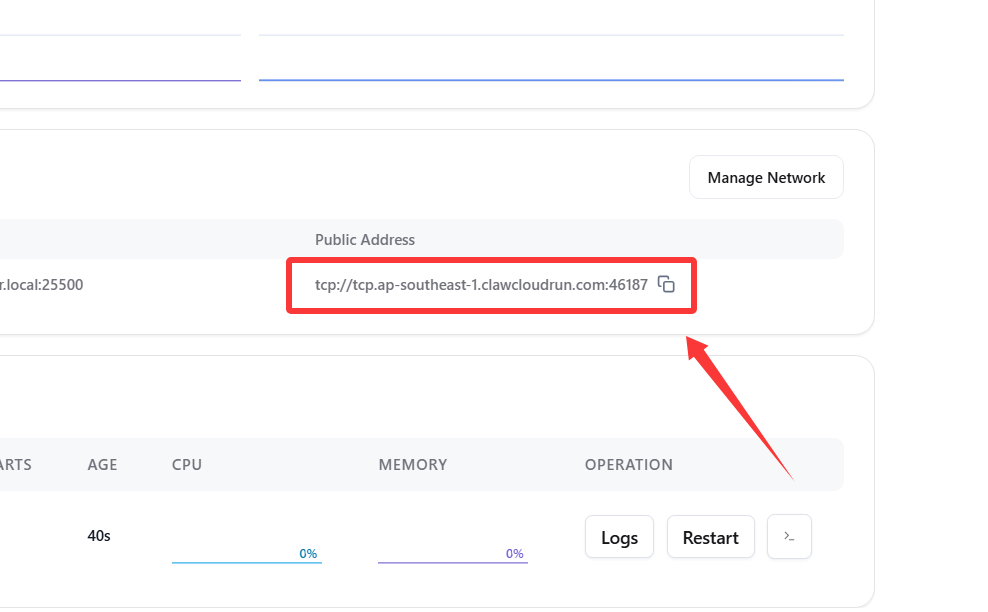
https://改为tcp://后,返回右上角点击Update更新部署。- 记录下分配的域名端口备用,例如 域名
tcp.ap-southeast-1.clawcloudrun.com端口46187。2️⃣ 前往 Cloudflare 添加一个
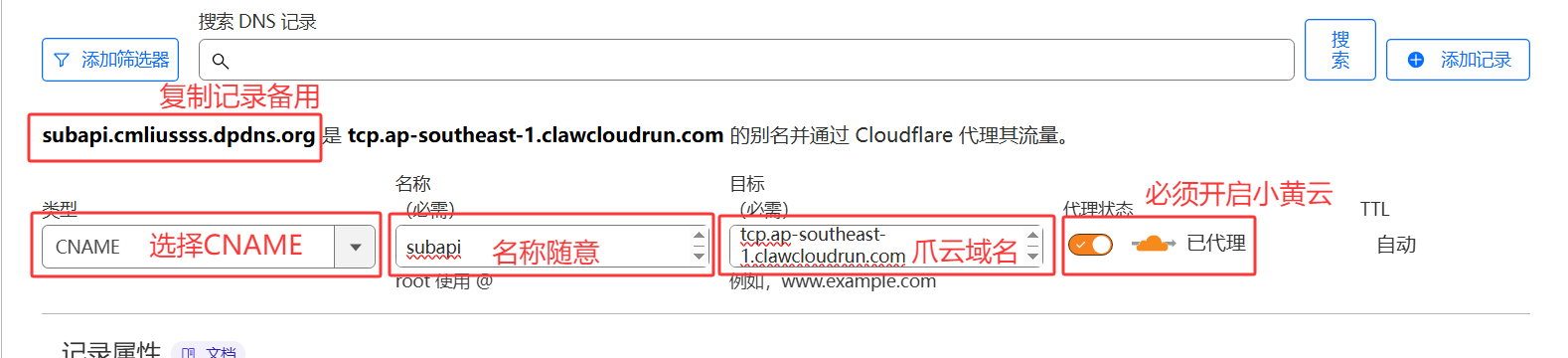
CNAME记录,前缀随意(但是不能是多级域名,不能出现
.),值必须填写爪云分配的域名,例如tcp.ap-southeast-1.clawcloudrun.com,并记录即将使用的自定义域 例如subapi.cmliussss.dpdns.org。3️⃣ 添加
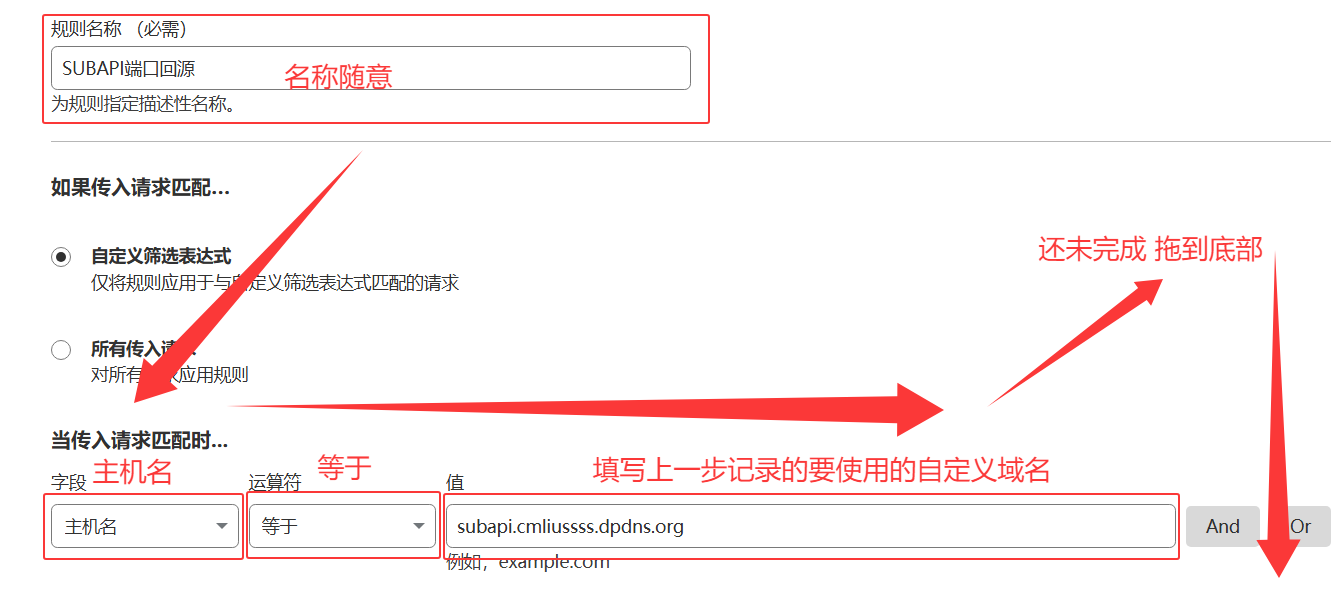
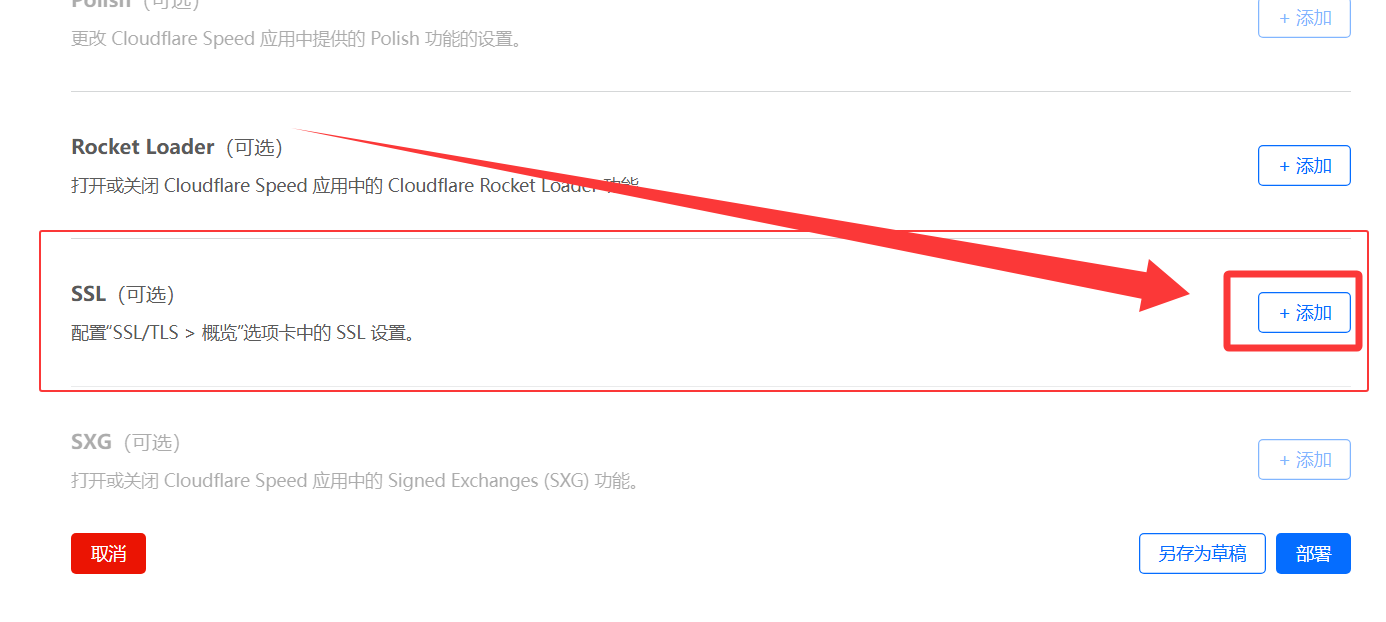
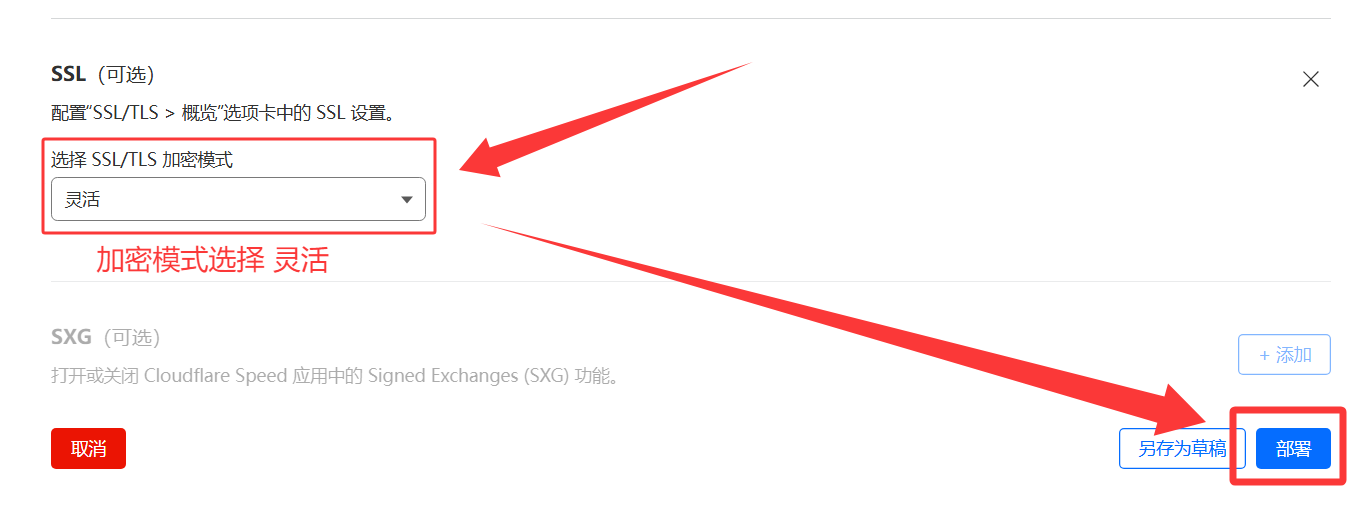
源服务器规则4️⃣ 添加
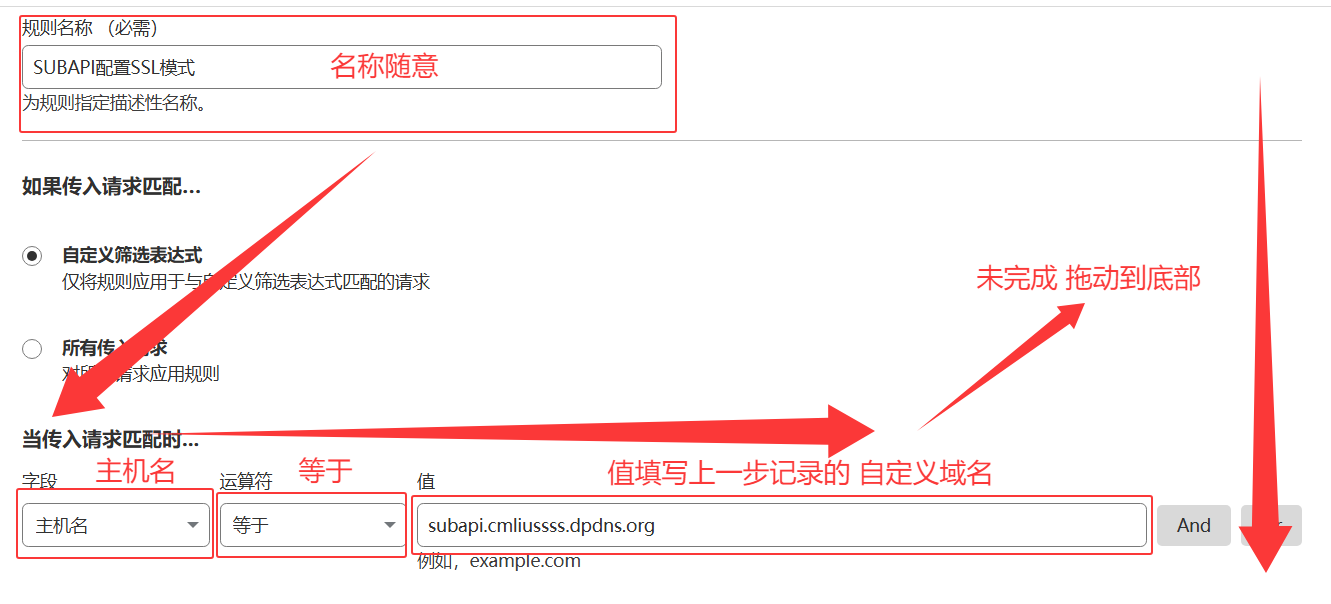
配置规则5️⃣ 完成!访问自定义域
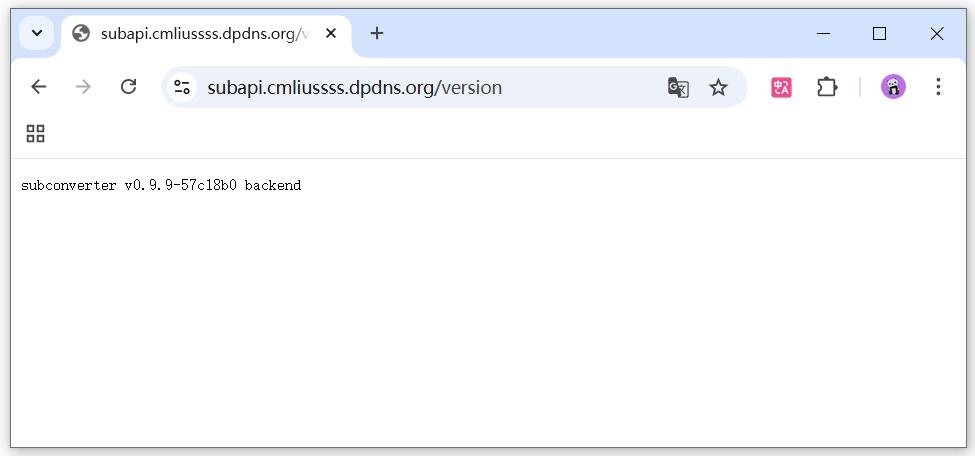
等待几分钟,访问 例如
https://subapi.cmliussss.dpdns.org/version即可访问到爪云容器。
新人Youtuber,需要您的支持,请务必帮我点赞、关注、打开小铃铛,十分感谢!!!



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
remove_duplicates
import asyncio
import os
import sys
from telethon import TelegramClient, errors
from telethon.tl.types import MessageMediaDocument, DocumentAttributeFilename
from dotenv import load_dotenv
# ================== 1. 读取配置 频道视频去重==================
load_dotenv()
try:
api_id = int(os.getenv("API_ID"))
api_hash = os.getenv("API_HASH")
PHONE_NUMBER = os.getenv("PHONE_NUMBER")
TWO_STEP_PASSWORD = os.getenv("TWO_STEP_PASSWORD") or None
# --- 修复:自动判断频道 ID 是数字还是用户名 ---
raw_target = os.getenv("TARGET_CHANNEL")
try:
# 如果是数字(如 -100xxx),转换为整数
TARGET_CHANNEL = int(raw_target)
except (ValueError, TypeError):
# 如果不是数字(如 @username),保持字符串
TARGET_CHANNEL = raw_target
# 扫描限制:设置为想要扫描的【视频数量】
scan_env = os.getenv("SCAN_LIMIT", "21000")
TARGET_VIDEO_COUNT = int(scan_env)
except Exception as e:
print(f"❌ 配置错误: {e}")
sys.exit(1)
client = TelegramClient("session/user_session", api_id, api_hash)
# ================== 2. 工具函数 ==================
def get_video_info(message):
"""
解析视频信息
返回: (is_video, file_id, file_name)
"""
if not message.media or not isinstance(message.media, MessageMediaDocument):
return False, None, None
doc = message.media.document
# 判定是否为视频 mime 类型
if not (doc.mime_type and doc.mime_type.startswith("video/")):
return False, None, None
# 获取文件名(仅用于显示,不用于判重)
file_name = "未知文件名"
for attr in doc.attributes:
if isinstance(attr, DocumentAttributeFilename):
file_name = attr.file_name
break
# Telethon document.id 是该文件在 TG 系统内的唯一标识
return True, doc.id, file_name
# ================== 3. 主逻辑 ==================
async def main():
print("🔐 正在登录 Telegram...")
# 自动处理登录,如果是第一次运行,控制台会要求输入验证码
await client.start(phone=PHONE_NUMBER, password=TWO_STEP_PASSWORD)
print("✅ 登录成功")
try:
# 获取频道实体对象
target = await client.get_entity(TARGET_CHANNEL)
target_name = getattr(target, "title", TARGET_CHANNEL)
except Exception as e:
print(f"❌ 无法获取频道信息: {TARGET_CHANNEL}")
print(f" 原因: {e}")
print(" 提示: 请确保你已经加入了该频道,且 ID 填写正确(ID必须是整数,不带引号)。")
return
# 显示当前任务模式
mode_str = "无限 (直到扫描完所有历史)" if TARGET_VIDEO_COUNT == 0 else f"最近 {TARGET_VIDEO_COUNT} 个视频"
print(f"\n📺 目标频道:{target_name}")
print(f"🎯 扫描目标:{mode_str}")
print(f"⚙️ 判重策略:保留【最新】发布的视频,删除旧的重复项")
print("-" * 40)
seen_keys = set() # 记录已出现的视频 ID
duplicates = [] # 存储待删除的消息 [(msg_id, file_name), ...]
scanned_msgs = 0 # 扫描过的消息总数(含文字/图片)
found_videos = 0 # 找到的视频数
print("⏳ 正在扫描消息 (顺序:从新 -> 旧)...")
# limit=None 表示如果不手动 break,就一直扫描下去
async for msg in client.iter_messages(target, limit=None):
scanned_msgs += 1
is_vid, file_id, file_name = get_video_info(msg)
if not is_vid:
continue
# 找到一个视频
found_videos += 1
# 核心判重逻辑
if file_id in seen_keys:
# 已经在 seen_keys 里,说明之前扫描到了(即更新的消息里有这个视频)
# 所以当前这条较旧的消息是重复的
duplicates.append((msg.id, file_name))
else:
seen_keys.add(file_id)
# 打印进度条
if found_videos % 20 == 0:
print(f" 已检索 {found_videos} 个视频 (总扫描消息 {scanned_msgs} 条)...")
# 达到数量限制,退出循环
if TARGET_VIDEO_COUNT != 0 and found_videos >= TARGET_VIDEO_COUNT:
print(f"✅ 已达到设定的 {TARGET_VIDEO_COUNT} 个视频目标,停止扫描。")
break
print("-" * 40)
print("📊 扫描结果统计")
print(f" 总扫描消息数:{scanned_msgs}")
print(f" 检索视频总数:{found_videos}")
print(f" 发现重复视频:{len(duplicates)}")
if not duplicates:
print("✅ 没有发现需要删除的重复视频")
return
print(f"\n⚠️ 即将删除 {len(duplicates)} 条【旧的重复】视频")
# 等待用户确认
confirm = input("❓ 确认删除?(输入 y 确认,其他键取消): ").strip().lower()
if confirm != "y":
print("🚫 已取消操作")
return
print("🗑️ 开始执行删除任务...")
# 提取所有要删除的消息 ID
delete_ids = [d[0] for d in duplicates]
batch_size = 50 # 每次删除 50 条,防止请求过大
for i in range(0, len(delete_ids), batch_size):
batch = delete_ids[i:i + batch_size]
try:
await client.delete_messages(target, batch)
print(f" 已删除 {min(i + batch_size, len(delete_ids))}/{len(delete_ids)}")
# 适当延时,保护账号安全
await asyncio.sleep(1.5)
except errors.FloodWaitError as e:
print(f"⏳ 触发 Telegram 流控 (FloodWait),需等待 {e.seconds} 秒...")
await asyncio.sleep(e.seconds + 2)
except errors.MessageIdInvalidError:
print(f"⚠️ 某些消息可能已经被删除,跳过该批次")
except Exception as e:
print(f"❌ 删除出错: {e}")
print(f"\n✅ 清理完成!")
# ================== 4. 程序入口 ==================
if __name__ == "__main__":
# 使用 with 语法自动管理连接和断开
with client:
client.loop.run_until_complete(main())TG-getnamelist
import os
import csv
import datetime
from telethon import TelegramClient
from dotenv import load_dotenv
# === 1. 读取配置 获取频道群组信息 ===
load_dotenv()
API_ID = os.getenv(“API_ID”)
API_HASH = os.getenv(“API_HASH”)
PHONE_NUMBER = os.getenv(“PHONE_NUMBER”)
TWO_STEP_PASSWORD = os.getenv(“TWO_STEP_PASSWORD”)
if not API_ID or not API_HASH:
print(“❌ 错误: 请确保 .env 文件中配置了 API_ID 和 API_HASH”)
exit(1)
client = TelegramClient(‘session/user_session’, int(API_ID), API_HASH)
def get_bot_api_id(entity, entity_type):
“””
根据实体类型将 Telethon ID 转换为 Bot API ID
Bot API 规则:
– 频道/超级群: -100 + ID
– 普通小群: – + ID
– 用户: ID (不变)
“””
raw_id = entity.id
if entity_type in [“频道”, “超级群”, “频道(未知)”]:
return int(f”-100{raw_id}”)
elif entity_type == “普通群”:
return int(f”-{raw_id}”)
else:
return raw_id
async def list_and_export_chats():
“””列出并导出账号加入的所有频道和群组”””
print(“📃 正在获取对话列表,请稍候…”)
chat_data_list = []
async for dialog in client.iter_dialogs():
entity = dialog.entity
entity_type = “未知”
# — 分类逻辑 —
if dialog.is_user:
entity_type = “私聊”
elif dialog.is_channel:
if getattr(entity, ‘broadcast’, False):
entity_type = “频道”
elif getattr(entity, ‘megagroup’, False):
entity_type = “超级群”
else:
entity_type = “频道(未知)”
elif dialog.is_group:
entity_type = “普通群”
# 过滤掉私聊 (如果需要私聊ID,注释掉下面这行)
if entity_type != “私聊”:
# 获取两种格式的 ID
raw_id = entity.id
bot_api_id = get_bot_api_id(entity, entity_type)
chat_info = {
“类型”: entity_type,
“名称”: dialog.name,
“Bot_API_ID”: bot_api_id, # ✅ 新增:可以直接给 Bot 用的 ID
“原始_ID”: raw_id, # Telethon 用的原始 ID
“用户名”: getattr(entity, ‘username’, ‘无’) or ‘无’,
“成员数”: getattr(entity, ‘participants_count’, ‘未知’)
}
chat_data_list.append(chat_info)
print(f”[{entity_type}] {dialog.name} | Bot_ID: {bot_api_id}”)
# === 导出到 CSV 文件 ===
if chat_data_list:
# — 文件夹处理逻辑 —
folder_name = “namelist”
if not os.path.exists(folder_name):
os.makedirs(folder_name)
print(f”📁 已自动创建文件夹: {folder_name}”)
timestamp = datetime.datetime.now().strftime(“%Y%m%d_%H%M%S”)
filename = f”telegram_chats_{timestamp}.csv”
# 使用 os.path.join 确保跨平台兼容性
file_path = os.path.join(folder_name, filename)
# 更新表头
headers = [“类型”, “名称”, “Bot_API_ID”, “原始_ID”, “用户名”, “成员数”]
try:
with open(file_path, mode=’w’, encoding=’utf-8-sig’, newline=”) as f:
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader()
writer.writerows(chat_data_list)
print(“-” * 50)
print(f”✅ 成功!共导出 {len(chat_data_list)} 个群组/频道。”)
print(f”📁 文件已保存到: {os.path.abspath(file_path)}”)
except Exception as e:
print(f”❌ 导出文件失败: {e}”)
else:
print(“⚠️ 未找到任何群组或频道。”)
async def main():
await client.start(phone=PHONE_NUMBER, password=TWO_STEP_PASSWORD)
print(“✅ 登录成功”)
await list_and_export_chats()
if __name__ == “__main__”:
with client:
client.loop.run_until_complete(main())
TG-forward-videos
import asyncio
import os
import random
import re
import logging
from logging.handlers import RotatingFileHandler
from typing import List, Dict, Optional
import aiosqlite
from telethon import TelegramClient, events
from telethon.tl.types import MessageMediaDocument, MessageMediaPhoto, Message
from telethon.errors import FloodWaitError
from dotenv import load_dotenv
# ==================== 1. 环境配置与初始化 ====================
DB_FOLDER = "database"
SESSION_FOLDER = "session"
for folder in [DB_FOLDER, SESSION_FOLDER]:
if not os.path.exists(folder):
os.makedirs(folder)
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - [%(name)s] - %(message)s",
handlers=[
RotatingFileHandler(os.path.join(DB_FOLDER, "bot_work.log"), maxBytes=10*1024*1024, backupCount=5, encoding="utf-8"),
logging.StreamHandler()
]
)
logger = logging.getLogger("SuperForwarder")
load_dotenv()
API_ID = int(os.getenv("API_ID", 0))
API_HASH = os.getenv("API_HASH", "")
PHONE_NUMBER = os.getenv("PHONE_NUMBER", "")
TWO_STEP_PASSWORD = os.getenv("TWO_STEP_PASSWORD", "")
TARGET_CHANNEL = int(os.getenv("TARGET_CHANNEL", 0))
SOURCE_CHANNELS = [int(x.strip()) for x in os.getenv("SOURCE_CHANNELS", "").split(",") if x.strip()]
# 配置参数
MAX_WORKERS = int(os.getenv("MAX_WORKERS", 3))
MIN_INTERVAL = float(os.getenv("MIN_INTERVAL", 2.0))
MAX_INTERVAL = float(os.getenv("MAX_INTERVAL", 5.0))
MIN_SIZE_MB = float(os.getenv("MIN_SIZE_MB", 0))
ALBUM_WAIT_TIME = 4.0 # 增加到4秒以确保相册收集完整
# 广告过滤正则
AD_PATTERNS = [
r"https?://\S+",
r"t\.me/\S+",
r"@\w+",
r"Via .*",
r"\[.*?\]\(https?://.*?\)"
]
# ==================== 2. 数据库管理 ====================
class AsyncDB:
def __init__(self, path):
self.path = path
self.conn: Optional[aiosqlite.Connection] = None
async def connect(self):
self.conn = await aiosqlite.connect(self.path)
await self.conn.execute("PRAGMA journal_mode=WAL;")
await self.conn.execute("""
CREATE TABLE IF NOT EXISTS progress (
channel_id TEXT PRIMARY KEY,
last_msg_id INTEGER DEFAULT 0,
min_msg_id INTEGER DEFAULT 0
)""")
await self.conn.execute("CREATE TABLE IF NOT EXISTS media_history (media_key TEXT PRIMARY KEY)")
await self.conn.execute("CREATE INDEX IF NOT EXISTS idx_mkey ON media_history (media_key);")
await self.conn.commit()
async def is_seen(self, key):
async with self.conn.execute("SELECT 1 FROM media_history WHERE media_key=?", (key,)) as cursor:
return await cursor.fetchone() is not None
async def mark_seen(self, key):
await self.conn.execute("INSERT OR IGNORE INTO media_history (media_key) VALUES (?)", (key,))
await self.conn.commit()
async def get_prog(self, cid):
async with self.conn.execute("SELECT last_msg_id, min_msg_id FROM progress WHERE channel_id=?", (str(cid),)) as cursor:
r = await cursor.fetchone()
return r if r else (0, 0)
async def update_prog(self, cid, last_id=None, min_id=None):
if last_id:
await self.conn.execute("INSERT INTO progress (channel_id, last_msg_id) VALUES (?, ?) ON CONFLICT(channel_id) DO UPDATE SET last_msg_id=?", (str(cid), last_id, last_id))
if min_id:
await self.conn.execute("INSERT INTO progress (channel_id, min_msg_id) VALUES (?, ?) ON CONFLICT(channel_id) DO UPDATE SET min_msg_id=?", (str(cid), min_id, min_id))
await self.conn.commit()
# ==================== 3. 工具逻辑 ====================
def clean_caption(text: str) -> str:
if not text: return ""
for p in AD_PATTERNS:
text = re.sub(p, "", text, flags=re.I)
return text.strip()
def is_media(msg: Message) -> bool:
"""判断消息是否为需要转发的媒体(视频或图片)"""
if not msg.media: return False
# 1. 处理视频
if isinstance(msg.media, MessageMediaDocument):
if msg.media.document.mime_type.startswith("video"):
if MIN_SIZE_MB > 0 and (msg.media.document.size / 1048576) < MIN_SIZE_MB:
return False
return True
# 2. 处理图片
if isinstance(msg.media, MessageMediaPhoto):
return True
return False
def get_media_key(msg: Message) -> Optional[str]:
"""获取媒体的唯一标识符"""
if isinstance(msg.media, MessageMediaDocument):
return f"doc_{msg.media.document.id}"
if isinstance(msg.media, MessageMediaPhoto):
return f"pho_{msg.media.photo.id}"
return None
# ==================== 4. 相册聚合逻辑 ====================
forward_queue = asyncio.Queue(maxsize=500)
pending_albums: Dict[int, List[Message]] = {}
async def push_to_queue_later(grouped_id):
await asyncio.sleep(ALBUM_WAIT_TIME)
if grouped_id in pending_albums:
msgs = pending_albums.pop(grouped_id)
if msgs:
msgs.sort(key=lambda x: x.id)
await forward_queue.put(msgs)
async def handle_incoming(msg: Message):
if msg.grouped_id:
if msg.grouped_id not in pending_albums:
pending_albums[msg.grouped_id] = []
asyncio.create_task(push_to_queue_later(msg.grouped_id))
pending_albums[msg.grouped_id].append(msg)
else:
await forward_queue.put([msg])
# ==================== 5. 转发 Worker ====================
async def worker(wid):
while True:
batch = await forward_queue.get()
try:
# 1. 检查这组消息里是否包含视频 (如果只想要带视频的组,不想要纯图片组)
has_video = any(
isinstance(m.media, MessageMediaDocument) and
m.media.document.mime_type.startswith("video")
for m in batch
)
if not has_video:
# logger.debug(f"Worker-{wid} | 跳过纯图片组")
forward_queue.task_done()
continue
# 2. 过滤已转发过的媒体
to_send = []
for m in batch:
m_key = get_media_key(m)
if m_key and not await db.is_seen(m_key):
to_send.append(m)
if to_send:
# 3. 提取文案
caption = ""
for m in batch:
if m.text:
caption = clean_caption(m.text)
break
# 4. 执行发送
files = [m.media for m in to_send]
await client.send_file(TARGET_CHANNEL, file=files, caption=caption, supports_streaming=True)
# 5. 标记已见
for m in to_send:
m_key = get_media_key(m)
if m_key: await db.mark_seen(m_key)
logger.info(f"Worker-{wid} | 成功转发 {len(to_send)} 个媒体文件 (包含视频及其关联图片)")
await asyncio.sleep(random.uniform(MIN_INTERVAL, MAX_INTERVAL))
except FloodWaitError as e:
logger.warning(f"Worker-{wid} | 触发限制,休眠 {e.seconds}s")
await asyncio.sleep(e.seconds + 5)
except Exception as e:
logger.error(f"Worker-{wid} 错误: {e}")
finally:
forward_queue.task_done()
# ==================== 6. 扫描任务 ====================
async def scan_latest_task(cid):
last_id, _ = await db.get_prog(cid)
if last_id == 0:
logger.info(f"频道 {cid} 初次运行,抓取最新 5000 条...")
async for msg in client.iter_messages(cid, limit=5000):
if is_media(msg): await handle_incoming(msg)
last_id = max(last_id, msg.id)
await db.update_prog(cid, last_id=last_id)
while True:
try:
async for msg in client.iter_messages(cid, min_id=last_id, reverse=True):
if is_media(msg): await handle_incoming(msg)
last_id = msg.id
await db.update_prog(cid, last_id=last_id)
await asyncio.sleep(60)
except Exception as e:
logger.error(f"实时同步出错: {e}")
await asyncio.sleep(30)
async def backfill_history_task(cid):
logger.info(f"历史补全启动: {cid}")
while True:
try:
_, min_id = await db.get_prog(cid)
if min_id <= 1:
logger.info(f"频道 {cid} 历史已全部同步完成。")
break
if forward_queue.qsize() < 100:
async for msg in client.iter_messages(cid, offset_id=min_id, limit=100):
if is_media(msg): await handle_incoming(msg)
min_id = msg.id
await db.update_prog(cid, min_id=min_id)
await asyncio.sleep(random.randint(20, 40))
else:
await asyncio.sleep(30)
except Exception as e:
logger.error(f"历史补全错误: {e}")
await asyncio.sleep(60)
# ==================== 7. 启动入口 ====================
s_tag = str(SOURCE_CHANNELS[0]) if SOURCE_CHANNELS else "unknown"
t_tag = str(TARGET_CHANNEL)
db_filename = f"{s_tag}to{t_tag}.db"
db_path = os.path.join(DB_FOLDER, db_filename)
session_path = os.path.join(SESSION_FOLDER, "forwarder_session")
client = TelegramClient(session_path, API_ID, API_HASH)
db = AsyncDB(db_path)
async def main():
await db.connect()
await client.start(PHONE_NUMBER, TWO_STEP_PASSWORD)
logger.info(f"--- 登录成功 | 数据库: {db_filename} ---")
for i in range(MAX_WORKERS):
asyncio.create_task(worker(i+1))
for cid in SOURCE_CHANNELS:
asyncio.create_task(scan_latest_task(cid))
async def backfill_wrapper(c):
await asyncio.sleep(10) # 延迟启动历史补全
await backfill_history_task(c)
asyncio.create_task(backfill_wrapper(cid))
await client.run_until_disconnected()
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
passKoyeb成功注册秘诀
在当今的技术世界中,无服务器(serverless)计算正在迅速成为一种流行的选择。今天,我想向大家介绍一个非常有前途的平台——Koyeb,它致力于简化云计算的部署和管理。随着技术的不断进步,无服务器计算将变得越来越重要。Koyeb作为这一领域的新星,凭借其强大的功能和优雅的设计,正在吸引越来越多的开发者和企业加入。如果你还没有尝试过Koyeb,不妨现在就去体验一下,相信你会有意想不到的收获!
介绍
什么是Koyeb?
Koyeb是一家提供无服务器计算平台的公司。简单来说,它让开发者可以专注于编写和部署代码,而无需担心服务器配置、维护和扩展等繁琐事务。
Koyeb的主要特点
- 无服务器架构
- 不用管理底层基础设施,只需专注于代码开发和部署。
- 自动扩展
- 根据流量和负载自动调整计算资源,确保应用在高峰期稳定运行。
- 全球分布
- 在全球多个地区有数据中心,可以选择最接近用户的数据中心,减少延迟。
- 多语言支持
- 支持Python、Node.js、Go等多种编程语言和框架。
- 集成和自动化
- 与GitHub、GitLab等版本控制系统无缝集成,支持CI/CD流水线,实现代码自动化部署。
- 高可用性和容错性
- 基础设施设计考虑了高可用性和容错性,保障应用在故障时仍能运行。
- 管理和监控
- 提供详细的应用监控和日志记录功能,帮助开发者了解应用的运行状况和性能瓶颈。
- 安全性
- 提供数据加密、身份验证和权限管理等多种安全措施,保障数据和应用的安全。
为什么选择Koyeb?
Koyeb通过其简便、高效且灵活的云计算解决方案,为开发者提供了从个人项目到大型企业应用的全面支持。如果你希望简化云计算部署和管理过程,Koyeb无疑是一个值得考虑的选择。
注册准备
指纹浏览器
- 下载、安装、注册账号

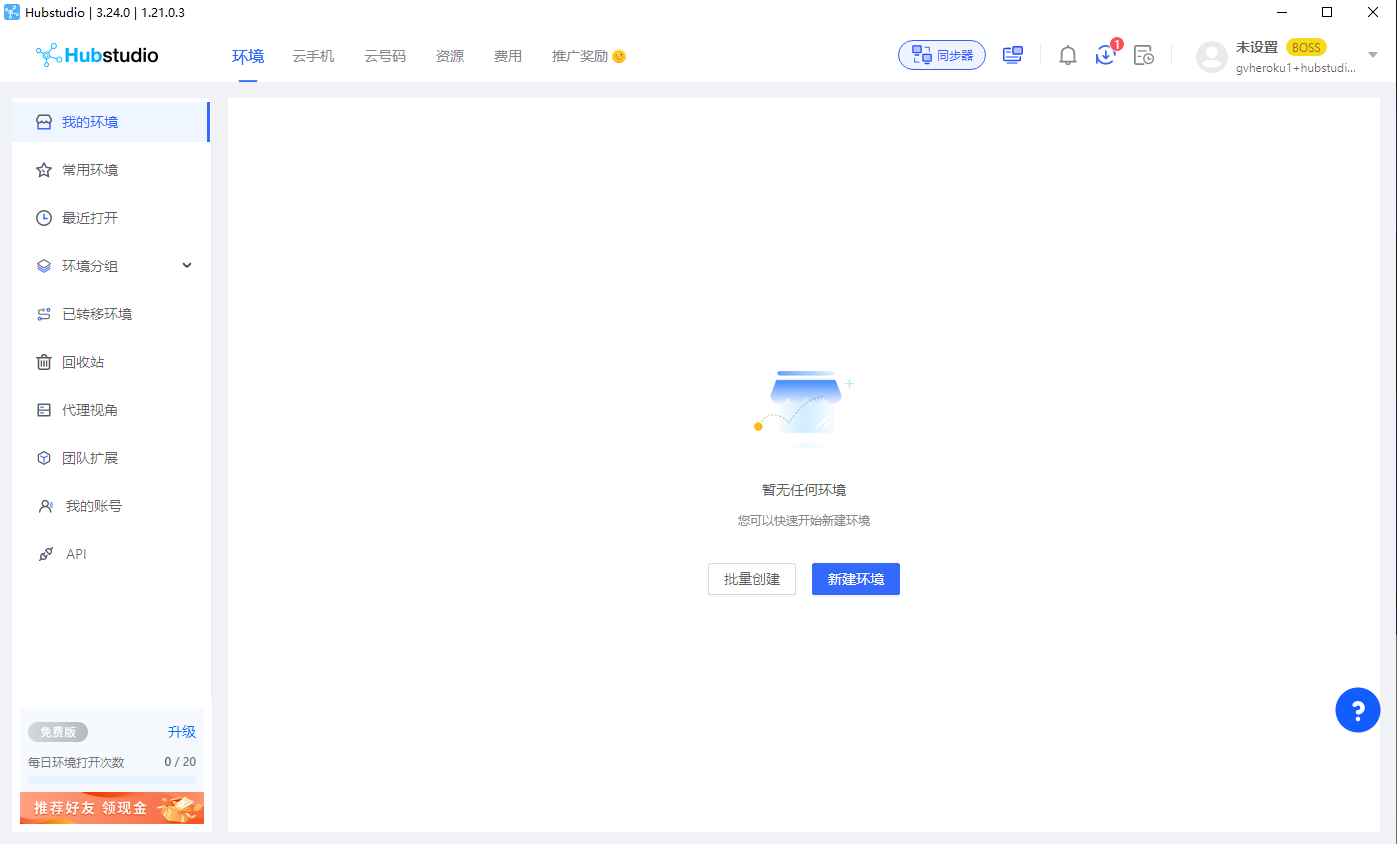
- 新建环境
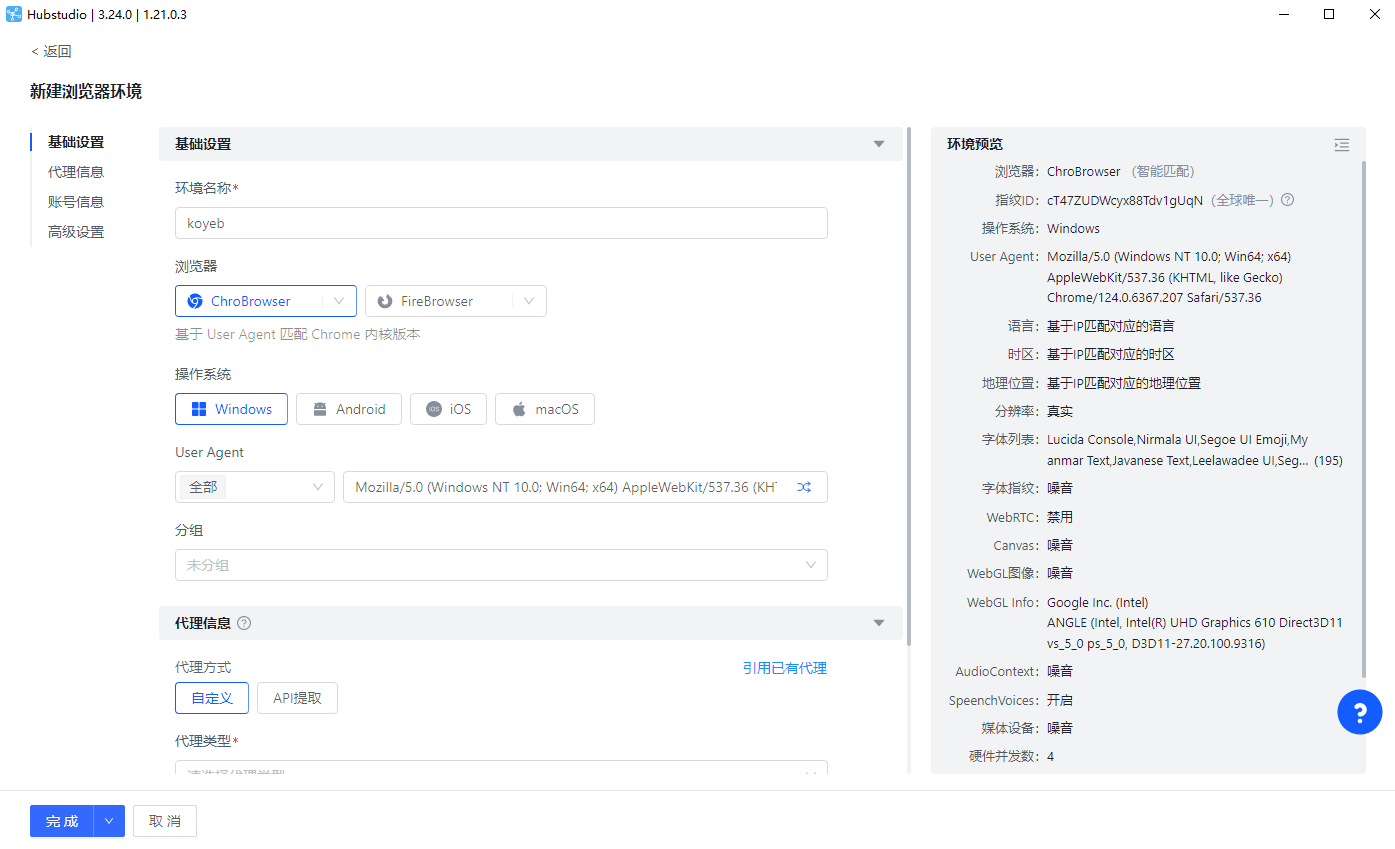
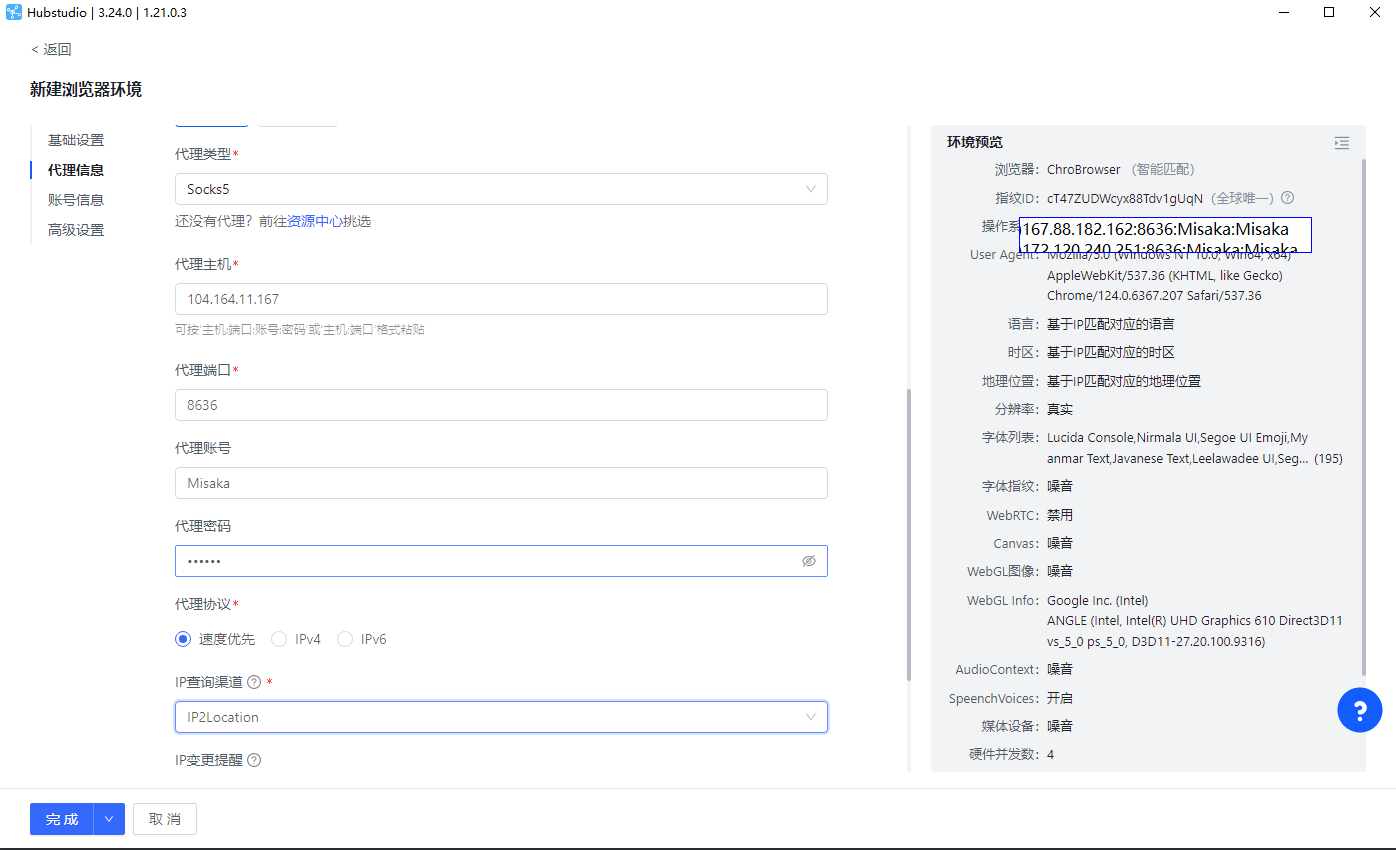
- 代理环境Sock5,提供一个Sock5代理协议IP:端口:账号:密码
PS:时效性不知,请在评论区留言!(Socks5)104.164.11.167:8636:Misaka:Misaka - 代理配置
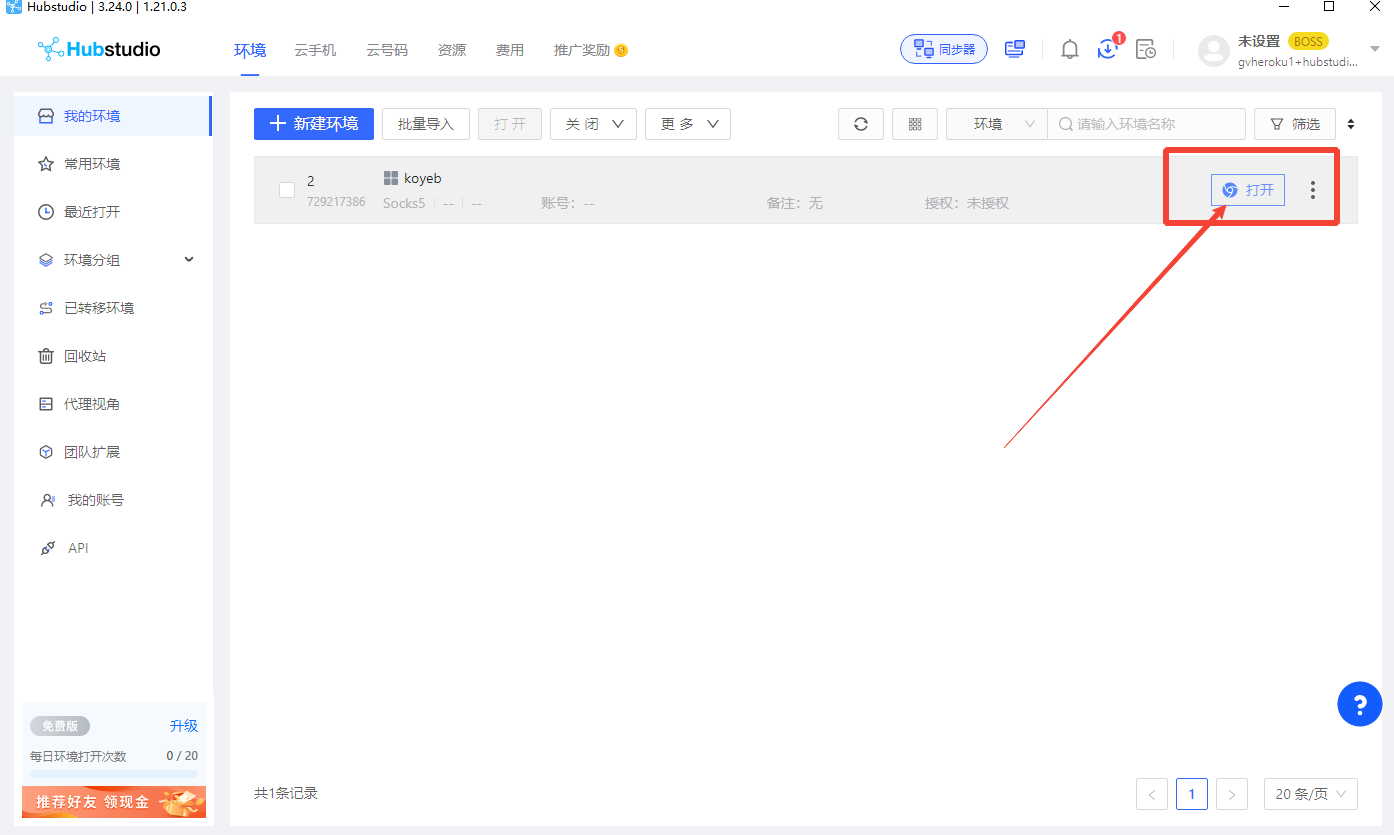
- 打开内置浏览器,检测环境是否为ISP干净环境(Good IP),如果是可以下一步啦
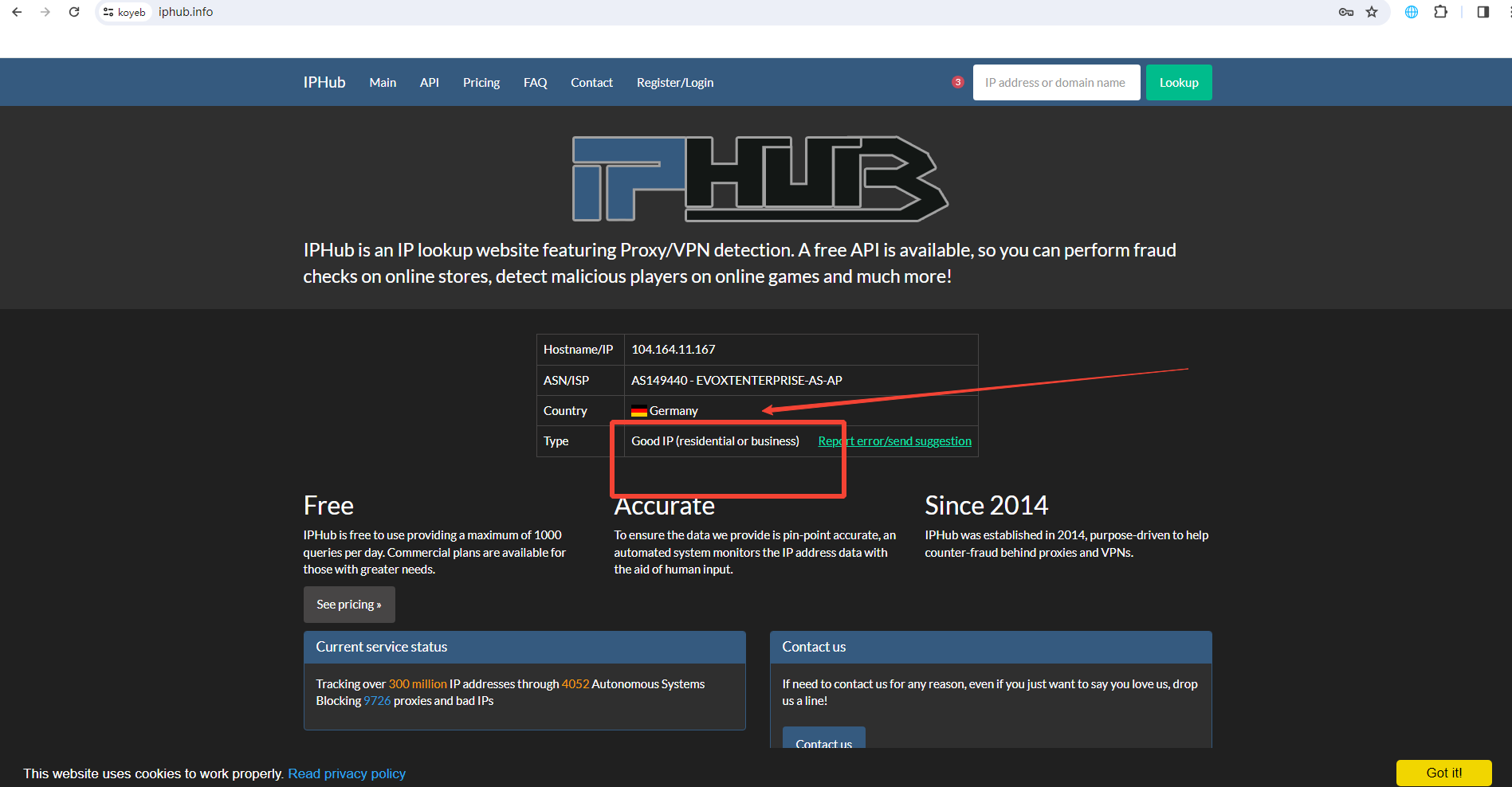
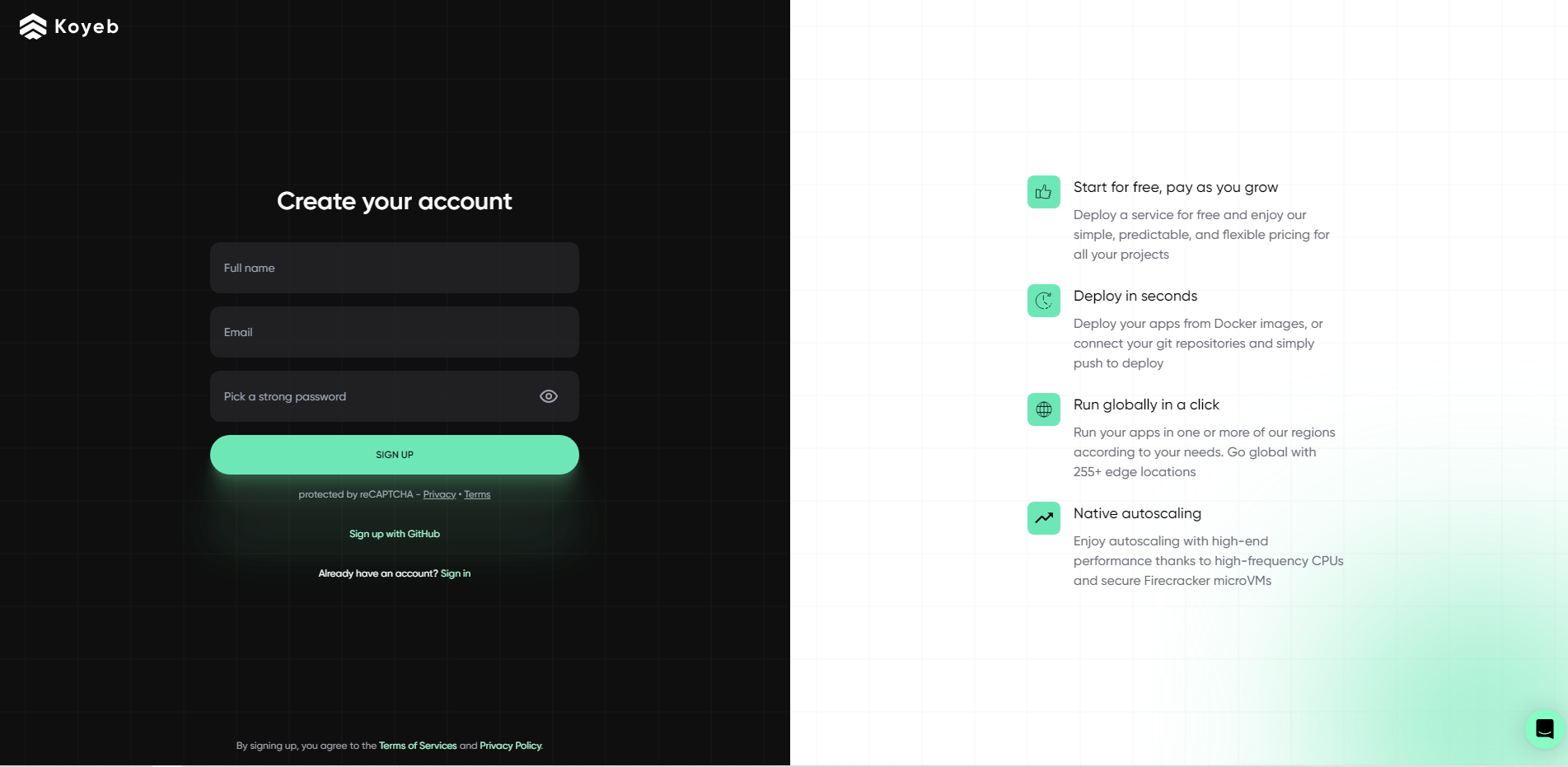
注册koyeb
- 注册koyeb,建议大厂邮箱注册。以下为注册成功。

常见问题
- 注册遇到绑卡,无法通过注册
- 注册环境不干净,请使用国外ISP环境注册。
- 通过注册,但是部署完项目几天后项目被停止
- koyeb长久不登陆一次会暂停项目服务;一般为7天。
- 通过注册,但是几天后被封号
- 未ISP环境注册。
- 部署项目不成功,提示环境不安全和项目违反网站规则
- 通过ISP环境首次注册成功后,部署任何项目都会成功并不会删号。
- 虽然注册成功,但是提示黄色信息认证
- 代表未通过ISP环境注册,项目可部署,但几天后会封号,再次提交信息认证无效,可通过本教程重新注册。
- 免费服务
- koyeb免费提供两个免费服务:德国和美国;仅支持创建一个免费项目。
- 付费服务
- koyeb提供多个付费服务:新加坡、日本和美国,服务均5$/月,绑卡可每月享受5.5$。
注册成功
- 用过以上截图注册成功后,网站会进入首页,首页不会出现任何信息认证提交或者绑卡信息,此为注册成功。
温馨提示
- 请勿在Koyeb平台上部署任何违反其使用规则的内容。禁止大量注册账号或过度使用资源,以免造成资源浪费。请遵守平台的使用规范,合理利用资源,共同维护一个良好的使用环境。
Wasmer 部署 WordPress 并绑定自定义域名教程
随着云计算和容器化技术的普及,开发者和网站管理员们对轻量、高效、灵活的部署方式需求越来越大。Wasmer 作为一款强大的 WebAssembly 运行时,提供了在多种平台上高性能运行 WebAssembly 程序的能力。本文将详细介绍如何在 Wasmer 平台上部署 WordPress,安装并配置 Farallon 主题,同时绑定自定义域名,实现一个独立、个性化的博客网站。
什么是 Wasmer?
Wasmer.io 是一款开源的 WebAssembly 运行时,支持通过 WebAssembly 技术在服务器端运行各种应用。借助 Wasmer,你可以:
- 运行用多种语言编写的 WebAssembly 模块。
- 实现跨平台部署,节省资源。
- 提高安全性,利用 WebAssembly 的沙盒机制。
将 WordPress 这种经典的 PHP + MySQL 网站运行于 Wasmer,既能利用现代技术优势,又能保证熟悉的 WordPress 体验。
网站介绍:WordPress + Farallon 主题
WordPress 作为全球最流行的内容管理系统(CMS),其强大、灵活和完善的生态为搭建博客提供了坚实基础。Farallon 是 WordPress 上一款优雅简洁、响应式设计的免费主题,适合写作和个人博客,具有:
- 干净简洁的界面。
- 高度可定制化。
- 良好的移动端兼容性。
- 支持多种布局和小工具。
通过此次部署,您将能搭建一个美观、轻便的个人博客。
一、准备工作
- 注册 Wasmer 账号:访问 https://wasmer.io 注册并登录。
- 购买或准备自定义域名:如从阿里云、华为云处购买,Hidns免费处申请。
- 注册Gcore托管平台:添加域名到Gcore,即可使用gcore的CDN和SSL。
- 准备 WordPress 镜像及数据库:wasmer自带一体化数据库,不需要额外的配置。
二、在 Wasmer 部署 WordPress
1. 注册并登录Wasmer


2. 部署 WordPress



3. 访问 WordPress 安装页面
访问地址:https://wordpress-mumt7.wasmer.app/



三、安装和配置 Farallon 主题
- 登录 WordPress 后台,访问 外观 > 主题。

- 点击 添加新主题,上传压缩包 Farallon。
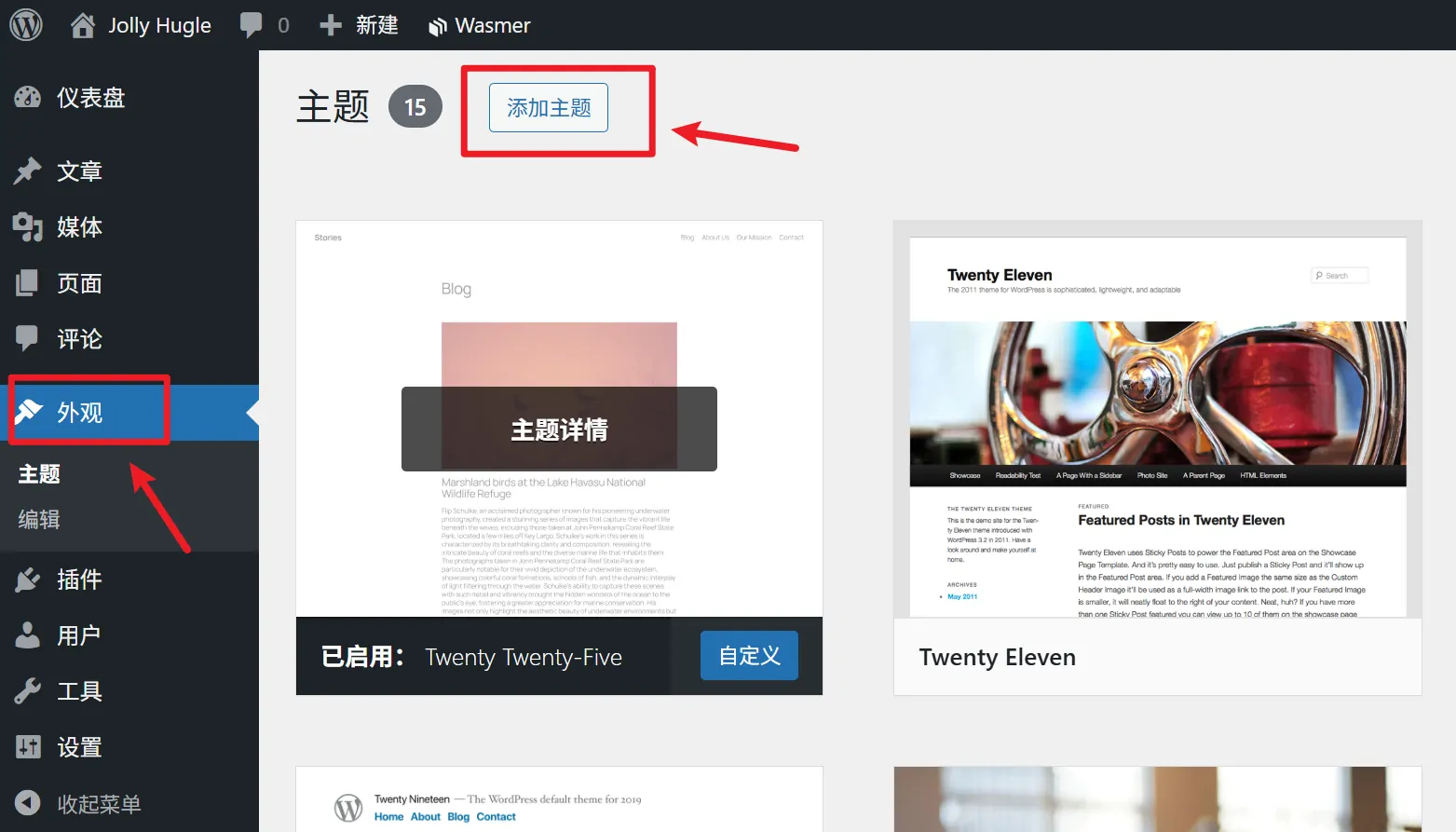
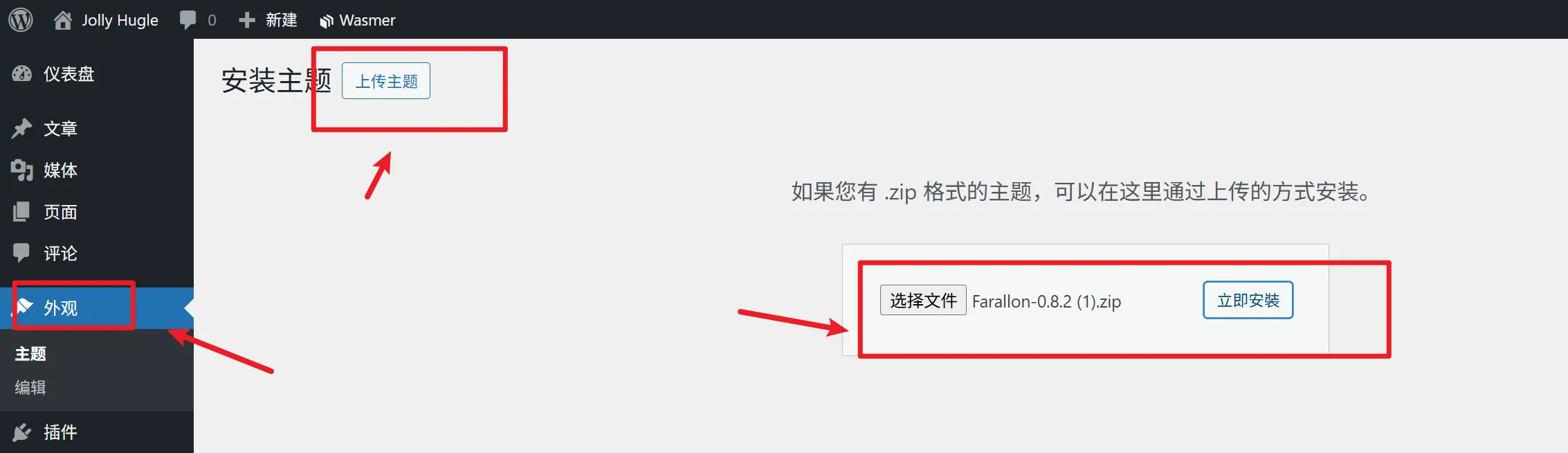
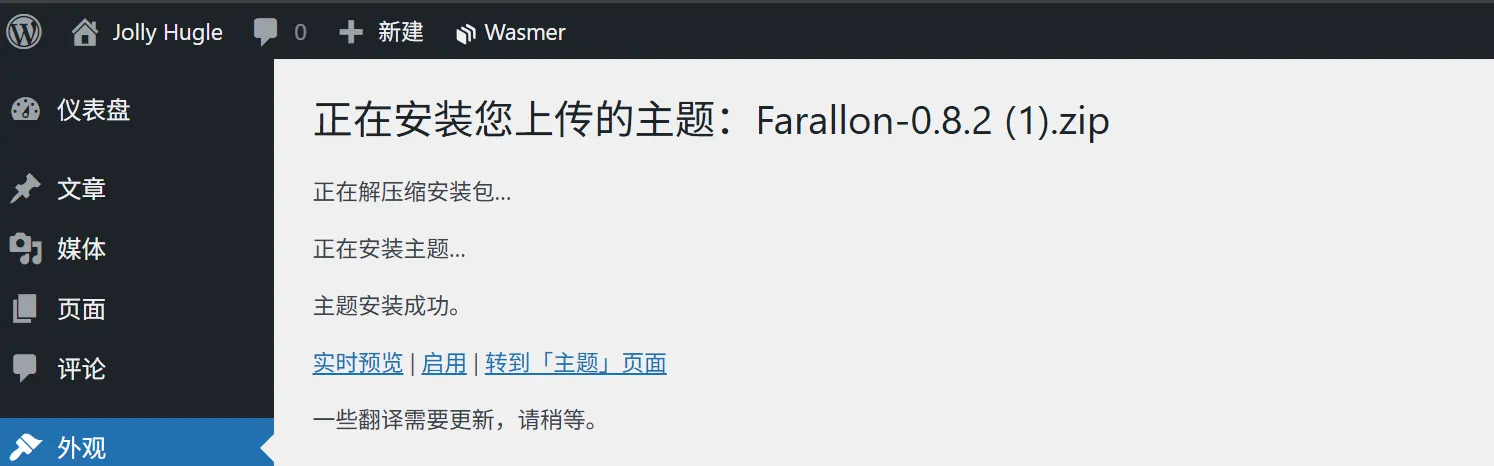
- 找到主题后,点击 安装,安装完成后点击 启用。
- 进入 自定义 > 主题选项 配置界面,根据需求调整网站配色、布局、小工具位置等。
- 发布首篇博客文章,体验主题效果。访问地址:https://www.2024921.xyz
四、托管Gcore平台
1. 注册并托管

2. 更新名称服务器
复制ns1.gcorelabs.net``ns2.gcdn.services到HiDNS的名称服务器中。

五、绑定自定义域名
1. 申请域名
HiDNS 永久免费域名计划网址,申请域名时不要只发工单,也要把域名申请一下。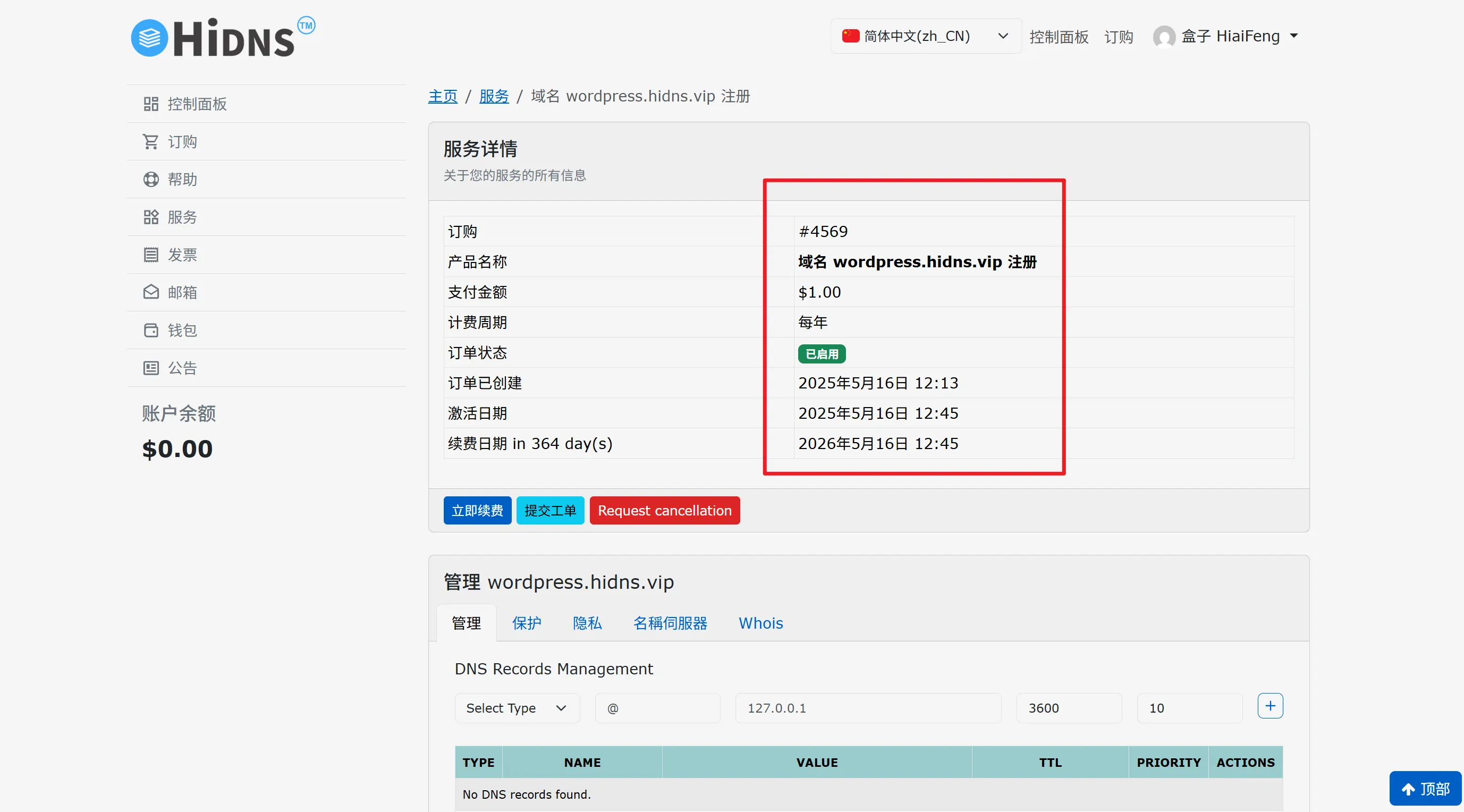

目前官方鼓励将域名使用于 Blog / 其他活跃的 Web 服务,并为域名申请 SSL 证书。符合该条件的用户可以直接注册,无须优惠劵,HiDNS 团队人员会在后台激活使用于“ Blog / 其他活跃的 Web 服务”的域名。域名激活后,7 天内完成 Blog 的绑定,会被设置为永久免费域名,只要域名不闲置、不滥用将永远免费。
2. 解析域名
登录域名管理控制台,添加一条 A 记录:
- 主机记录:
@或自定义子域名(如www) - 记录类型:
A - 记录值:Wasmer 实例公网 IP 地址
- TTL:默认即可
等待 DNS 生效(通常几分钟到一小时不等)。
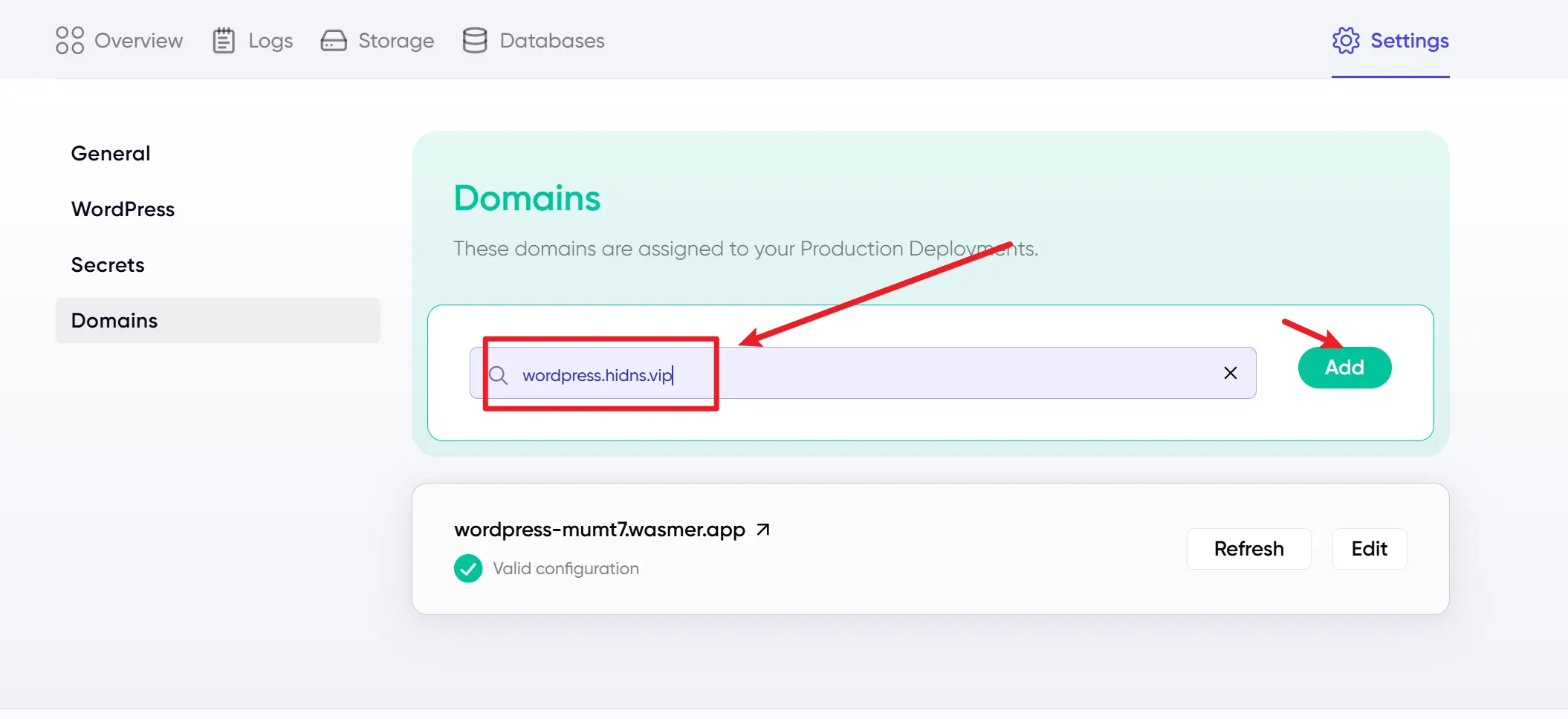
3. 配置 Wasmer 绑定域名
在 Wasmer 平台:
- 找到你的 WordPress 服务对应的项目设置。
- 在“域名”或“网络”栏目,绑定你的自定义域名。
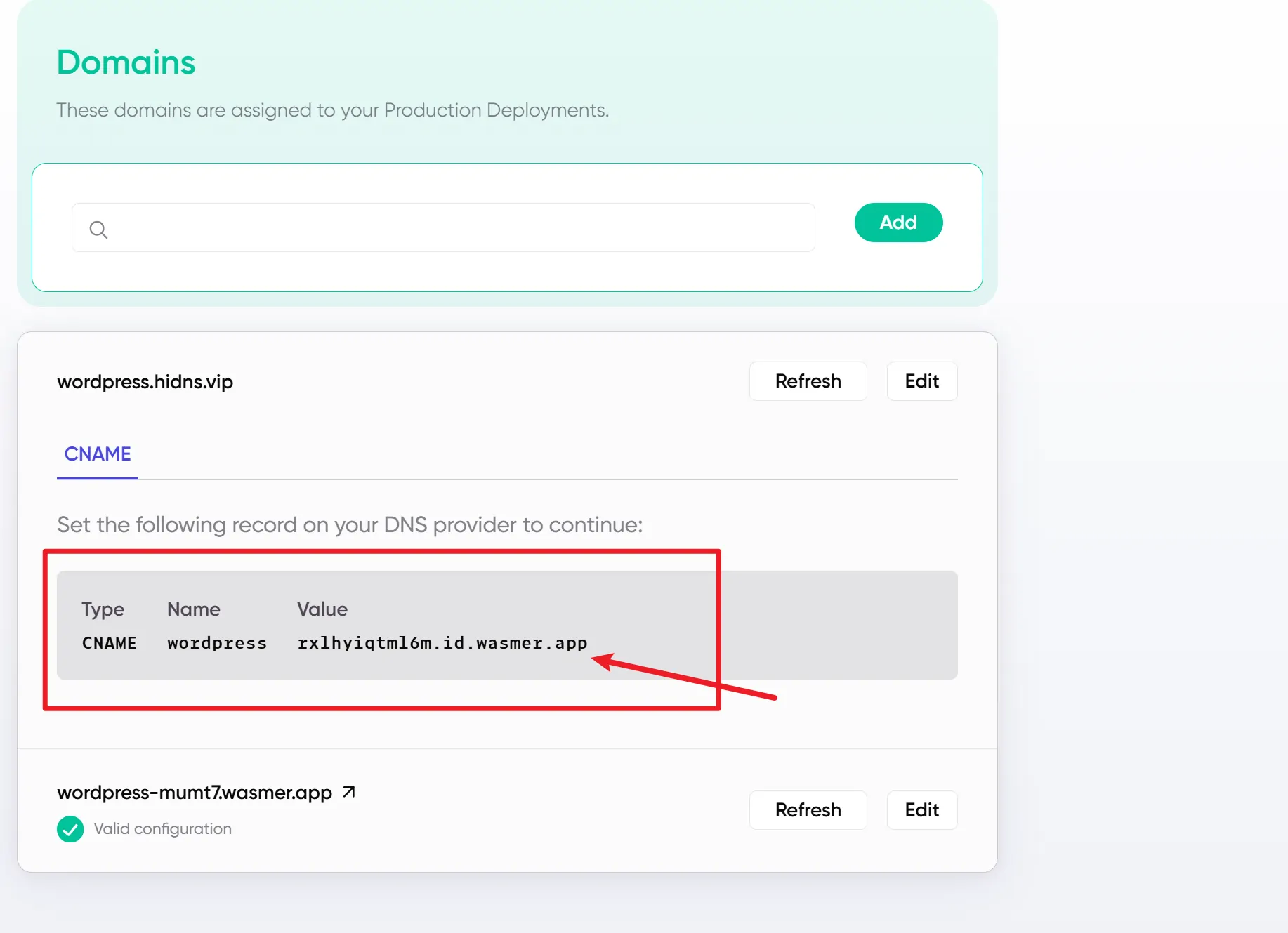
- 将Value值添加到Gcore的CDN中,即可绑定成功。
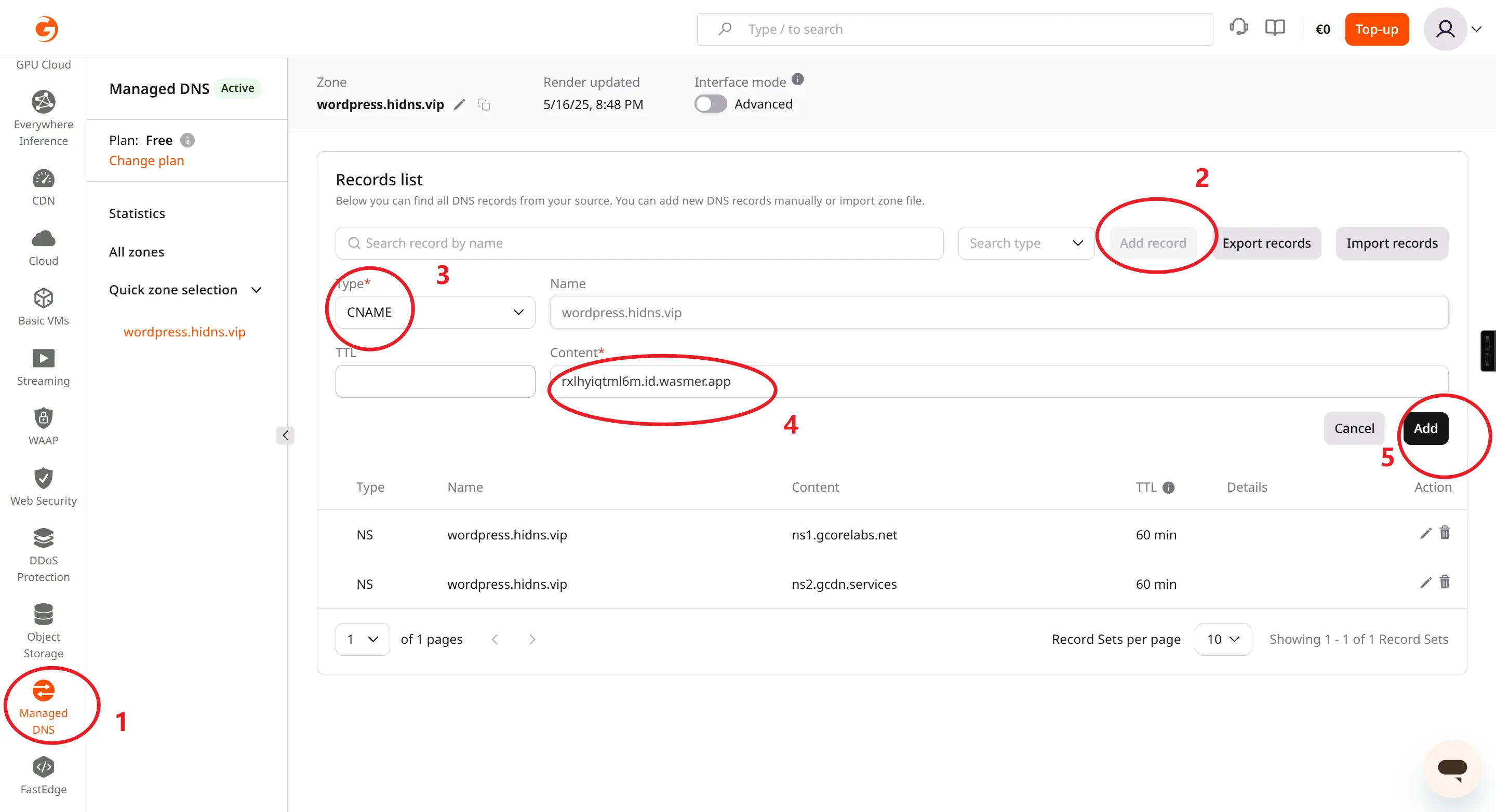
- 绑定后,Wasmer 会自动配置监听你的域名请求。
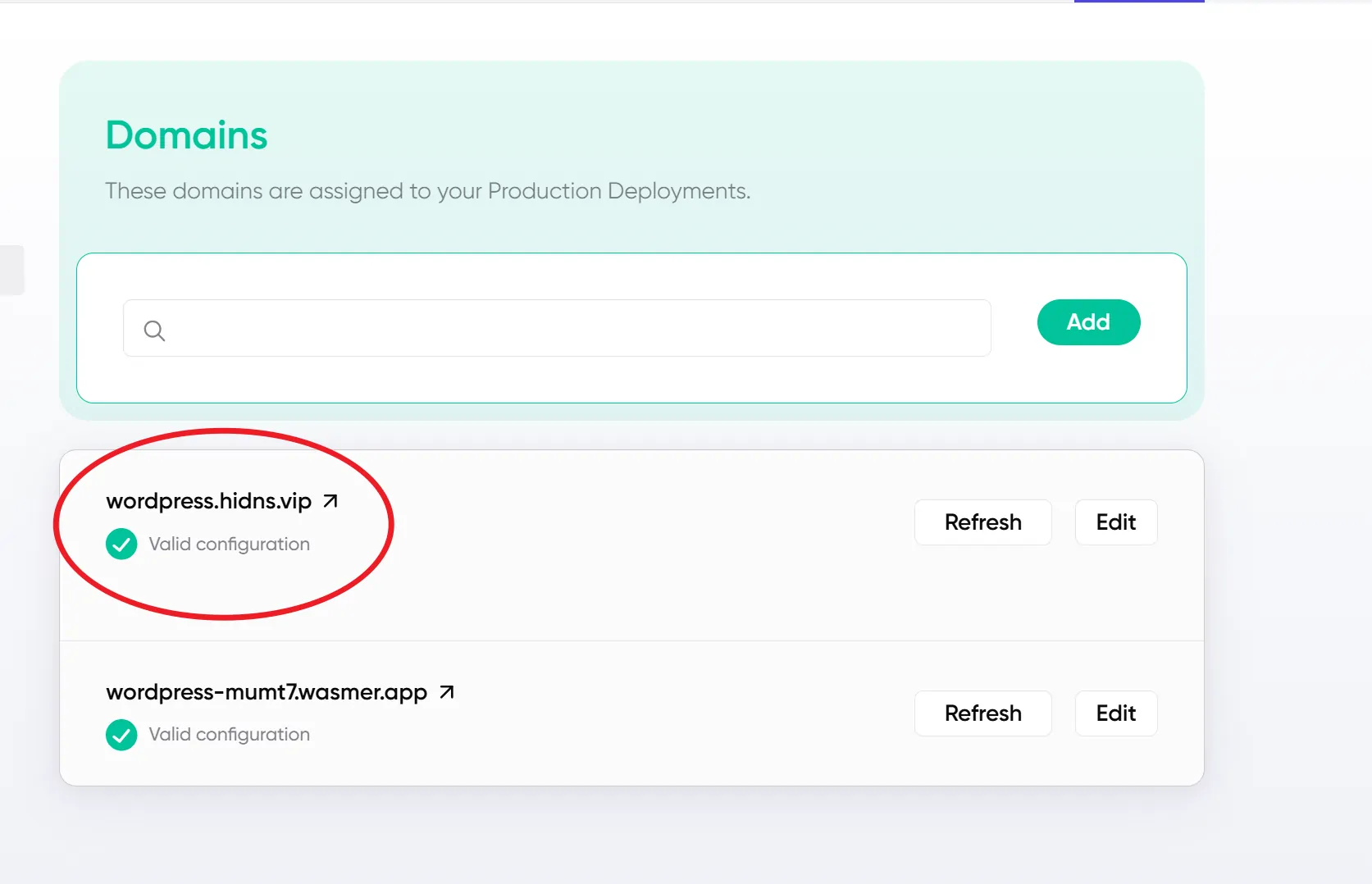
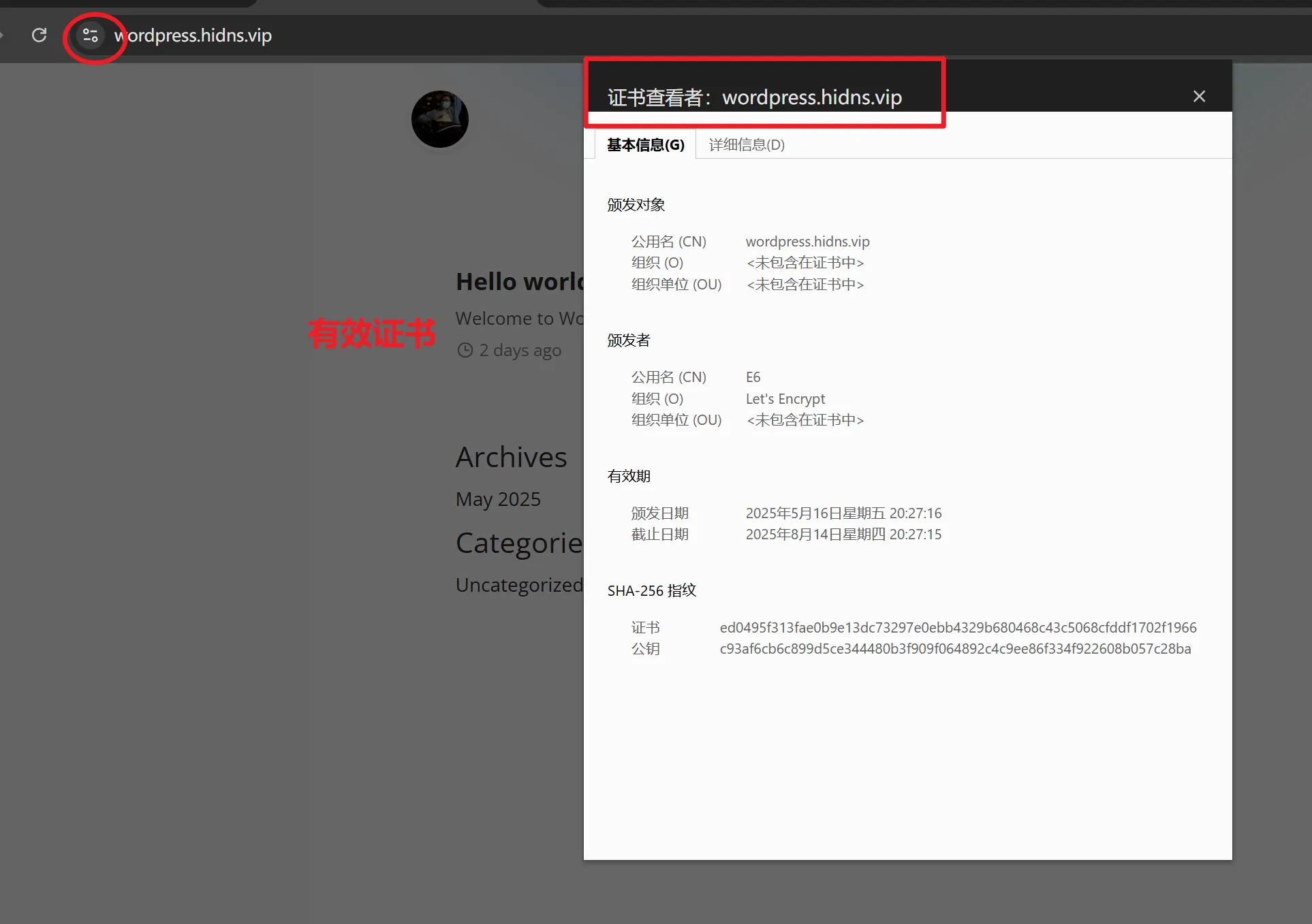
六、总结
通过 Wasmer,我们实现了现代、轻量级的 WordPress 部署方式,极大提升了网站的安全性和跨平台能力。搭配 Farallon 主题,赋予博客简洁优雅的外观体验。绑定自定义域名后,网站变得更具专业性。无论是个人博客还是小型站点,这套方案都非常适合。
如果你正在寻找一套高性能又易用的部署方案,试试 Wasmer 无疑是一个不错的选择!